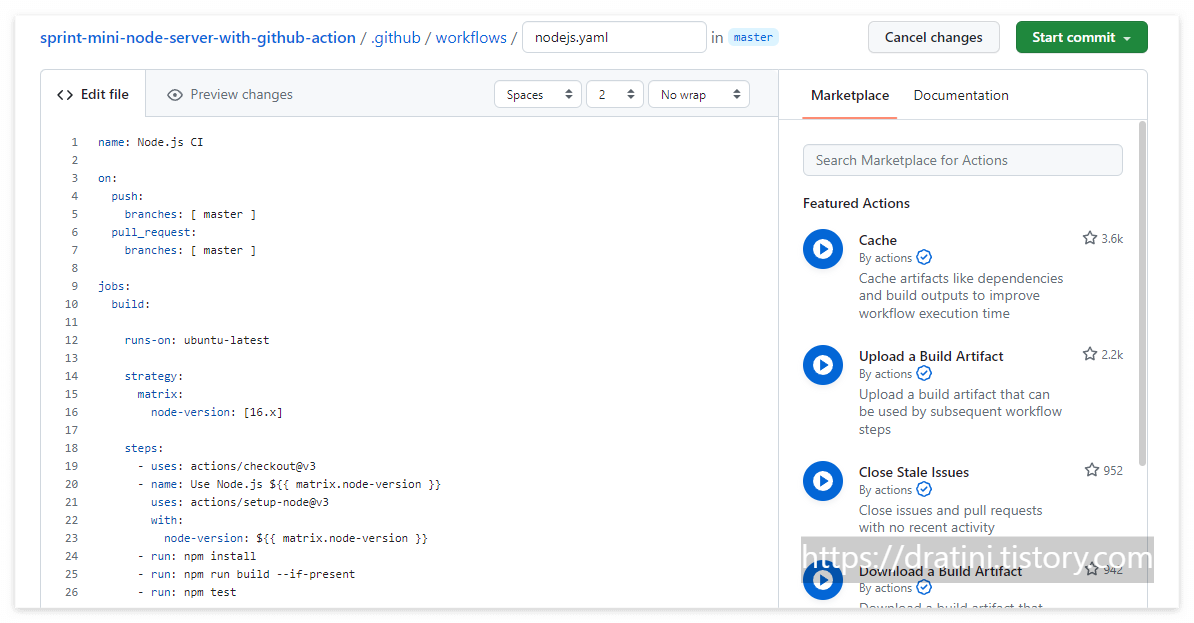
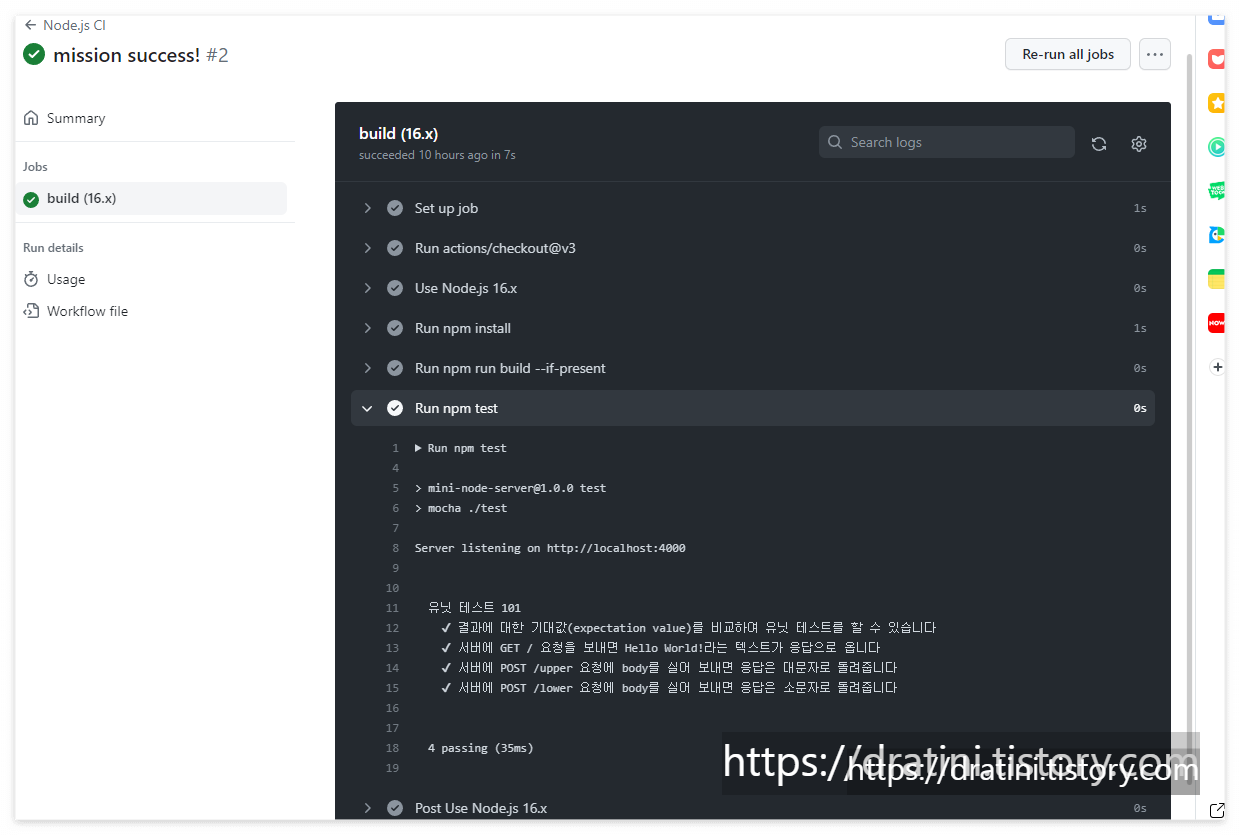
배포 자동화
배포 자동화란 한 번의 클릭 혹은 명령어 입력을 통해 전체 배포 과정을 자동으로 진행하는 것을 말합니다.
배포자동화 장점
- 먼저 수동적이고 반복적인 배포 과정을 자동화함으로써 시간이 절약됩니다.
- 휴먼 에러(Human Error)를 방지할 수 있습니다. 여기서 휴먼 에러란 사람이 수동적으로 배포 과정을 진행하는 중에 생기는 실수를 뜻합니다. 배포 자동화를 통해 전체 배포 과정을 매번 일관되게 진행하는 구조를 설계하여 휴먼 에러 발생 가능성을 낮출 수 있습니다.
배포 자동화 파이프라인

배포에서 파이프라인(Pipeline)이란 용어는 소스 코드의 관리부터 실제 서비스로의 배포 과정을 연결하는 구조를 뜻합니다.
파이프라인은 전체 배포 과정을 여러 단계(Stages)로 분리하는데, 각 단계는 파이프라인 안에서 순차적으로 실행되며, 단계마다 주어진 작업(Actions)을 수행합니다.
파이프라인을 여러 단계로 분리할 때, 대표적으로 쓰이는 세 가지 단계가 존재합니다.
- Source 단계: Source 단계에서는 원격 저장소에 관리되고 있는 소스 코드에 변경 사항이 일어날 경우, 이를 감지하고 다음 단계로 전달하는 작업을 수행합니다.
- Build 단계: Build 단계에서는 Source 단계에서 전달받은 코드를 컴파일, 빌드, 테스트하여 가공합니다. 또한 Build 단계를 거쳐 생성된 결과물을 다음 단계로 전달하는 작업을 수행합니다.
- Deploy 단계: Deploy 단계에서는 Build 단계로부터 전달받은 결과물을 실제 서비스에 반영하는 작업을 수행합니다.
여기서 주의해야 할 점은 파이프라인의 단계는 상황과 필요에 따라 더 세분화되거나 간소화될 수 있다는 겁니다.
AWS 개발자 도구
AWS에는 개발자 도구 섹션이 존재합니다. 개발자 도구 섹션에서 제공하는 서비스를 활용하여 배포 자동화 파이프라인을 구축할 수 있습니다.

본격적인 배포 자동화 실습을 진행하기 전에, 배포 자동화 과에서 사용하는 AWS 서비스들에 대해서 간략하게 소개하는 시간을 가져보도록 하겠습니다.
CodeCommit
Source 단계를 구성할 때 CodeCommit 서비스를 이용합니다. CodeCommit은 GitHub과 유사한 서비스를 제공하는 버전 관리 도구입니다. CodeCommit과 GitHub의 차이점은 무엇일까요? 어떤 서비스가 우월하다기보다, 각 서비스가 가지는 장단점이 다릅니다.
GitHub과 비교했을 때 CodeCommit 서비스는 보안과 관련된 기능에 강점을 가집니다. 소스 코드의 유출이 크게 작용하는 기업에서는 매우 중요한 요소입니다. 다만 CodeCommit을 사용할 때는 과금 가능성을 고려해야 합니다. 프리티어 한계 이상으로 사용할 시 사용 요금이 부과될 수도 있습니다. 그런 이유로 사이드 프로젝트나 가볍게 작성한 소스 코드를 저장해야 할 경우에는 GitHub을 이용하는 것이 효과적이라고 볼 수 있습니다.
CodeBuild
Build 단계에서는 CodeBuild 서비스를 이용합니다. CodeBuild 서비스를 통해 유닛 테스트, 컴파일, 빌드와 같은 빌드 단계에서 필수적으로 실행되어야 할 작업을 명령어를 통해 실행할 수 있습니다.
CodeDeploy
Deploy 단계를 구성할 때는 기본적으로 다양한 서비스를 이용할 수 있습니다. 이번 실습에서는 CodeDeploy와 S3 서비스를 이용할 예정입니다. CodeDeploy 서비스를 이용하면 실행되고 있는 서버 애플리케이션에 실시간으로 변경 사항을 전달할 수 있습니다. 또한 S3 서비스를 통해 S3 버킷을 통해 업로드된 정적 웹 사이트에 변경 사항을 실시간으로 전달하고 반영할 수 있습니다.
CodePipeline
각 단계를 연결하는 파이프라인을 구축할 때 CodePipeline 서비스를 이용합니다.
'DevOps' 카테고리의 다른 글
| [DevOps] 4/24 TIL : 배포 자동화 실습 - Server (0) | 2023.04.26 |
|---|---|
| [DevOps] 4/24 TIL : 배포 자동화 실습 - Client (0) | 2023.04.24 |
| [DevOps] 4/20 TIL : GitHub Action을 사용한 테스트 자동화 실습 (0) | 2023.04.21 |
| [DevOps] 4/20 TIL : CI/CD, 지속적 통합, 테스트 (0) | 2023.04.20 |
| [DevOps] 4/11 TIL : Docker 개념부터 기본 설치까지(Ubuntu) (0) | 2023.04.11 |