Kubernetes 관리 툴 K9s
Kubernetes 클러스터를 효과적으로 관리하는 일은 매우 복잡할 수 있습니다. 그러나 K9s라는 터미널 기반 UI 툴을 사용하면 이러한 복잡성을 크게 줄일 수 있습니다. 이번 블로그 포스트에서는 K9s의 주요 기능과 설치 방법, 사용법에 대해 자세히 알아보겠습니다.
K9s
K9s는 Kubernetes 클러스터와 상호 작용하기 위해 설계된 CLI(명령줄 인터페이스) 도구입니다. 실시간으로 클러스터의 리소스를 관리, 모니터링, 문제 해결할 수 있도록 직관적인 인터페이스를 제공합니다.
주요 기능
- 클러스터 리소스의 실시간 모니터링
- Pod, 서비스, 배포 등을 보기 위한 인터랙티브 UI
- 사용자 정의 레이아웃 및 뷰 지원
- 빠른 탐색과 작업을 위한 단축키
- 고급 필터링 및 검색 기능
이 기능들을 몇개의 단축키로 쉽게 사용할 수 있습니다.
K9s 설치 방법
먼저 k9s를 설치하기 전에 kubectl이 설치되어있어야 합니다.
kubectl 설치방법은 kubectl - 쿠버네티스 클러스터를 관리해보자! 문서를 참조해주세요
Linux:
curl명령어를 사용해 바이너리 파일 다운로드 합니다.
curl -sS https://github.com/derailed/k9s/releases/latest/download/k9s_Linux_x86_64.tar.gz | tar -xz
sudo mv k9s /usr/local/bin/macOS:
brew 명령어를 사용해 설치합니다.
brew install k9sWindows:
방법 1 : Windows용 바이너리를 K9s GitHub releases 페이지에서 다운로드하고 PATH에 추가합니다.
방법 2 : chocolatey를 사용해 설치합니다.
choco install k9sK9s 시작하기
설치 후 K9s를 실행하려면 간단히 다음 명령어를 입력합니다:
k9s
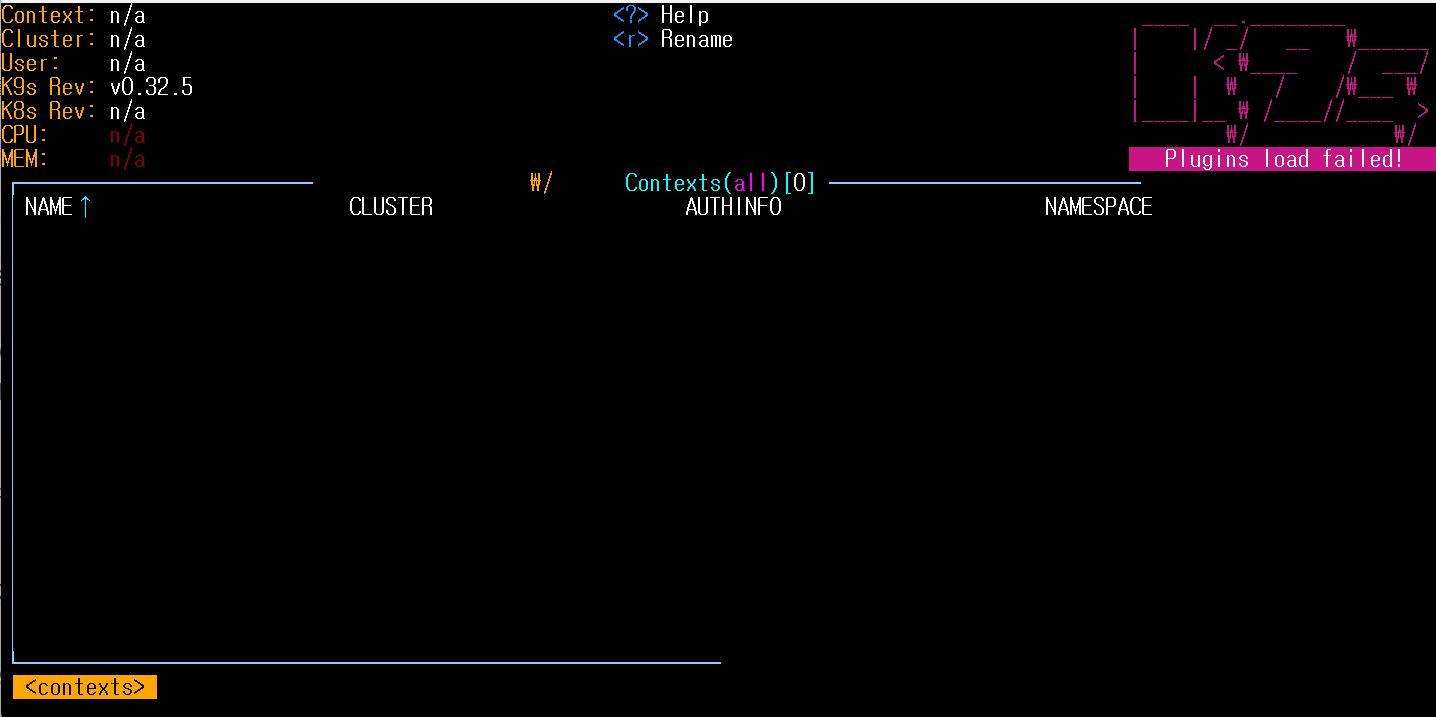
이 명령어를 입력하면 K9s 대시보드가 열리고, 여기서 Kubernetes 클러스터에 연결하여 리소스를 관리할 수 있습니다
K9s 사용법
리소스 보기
- 기본 네비게이션: 화살표 키를 사용하여 리소스 유형 간 이동, Enter 키를 눌러 특정 리소스의 자세한 정보를 확인할 수 있습니다.
- Pod 로그 보기: l 또는 :logs
- Pod로 실행: e 또는 :exec
- 포트 포워딩: f 또는 :port-forward
리소스 필터링 및 검색
- 명령 바: :를 사용하여 명령 바에 접근
- 필터 적용: :filter status=Running 등 필터를 적용하여 리소스 좁히기
- 검색: :search my-pod 등으로 이름 또는 라벨로 리소스 검색
리소스 관리
- 리소스 설명: d를 눌러 리소스 설명 확인
- 리소스 편집: e를 눌러 YAML 파일 편집
- 리소스 삭제: d를 눌러 리소스 삭제
고급 기능
뷰 커스터마이징
- :view 명령어를 사용하여 레이아웃을 사용자 정의
- :view save 및 :view load로 커스텀 뷰 저장 및 불러오기
단축키 및 명령어
- ?를 눌러 사용 가능한 모든 단축키 목록 확인
- : 명령 바를 사용하여 K9s 명령어 실행
참고
'DevOps' 카테고리의 다른 글
| Kubectl - 쿠버네티스 클러스터를 관리해보자! (0) | 2023.08.14 |
|---|---|
| [DevOps] 최종 프로젝트 회고 - 일정 및 작업 관리 (0) | 2023.07.11 |
| [DevOps] 최종 프로젝트 - 구현(IaC) (0) | 2023.06.20 |
| [DevOps] 최종 프로젝트 회고 - 구현(클라우드 리소스) (0) | 2023.06.20 |
| [DevOps] 최종 프로젝트 회고 - 구현(CI/CD) (0) | 2023.06.19 |