프로젝트 2를 진행하면서 해결해야할 여러 문제상황들을 마주했다.
그래서 주요 문제상황과 그 상황을 어떻게 해결했는지 기록했다.
ISSUE SOLUTION LOG
📝 문제 1 : 아마존 ECR IAM ROLE 생성
- 상황 : access key를 이용하지 않고 ECR에 로그인하기 위해 IAM ROLE 생성
- 해결 방안 : OpenID Connection을 이용해 GitHub Actions 워크플로가 액세스 키, 시크릿 키를 노출하지 않고 AWS(Amazon Web Services)의 리소스에 액세스 가능
- 참고자료
- 해결 과정
- IAM 자격 증명 공급자 리소스를 생성
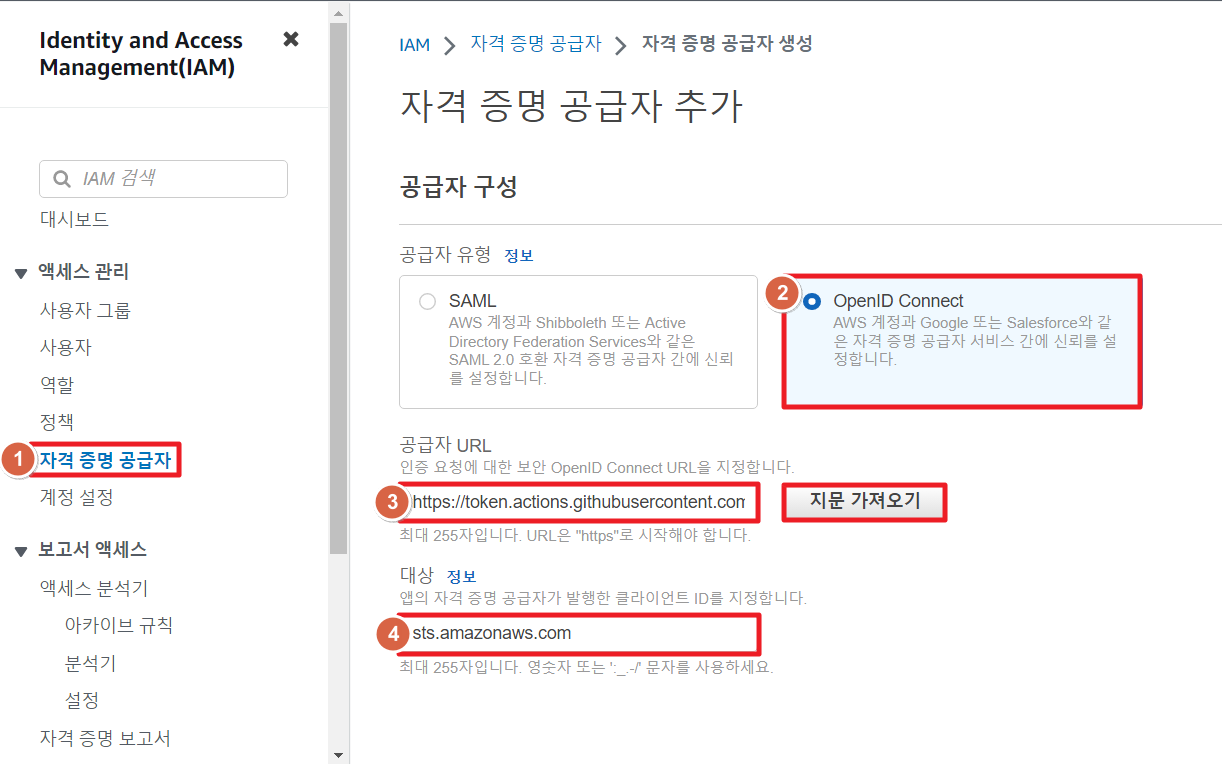
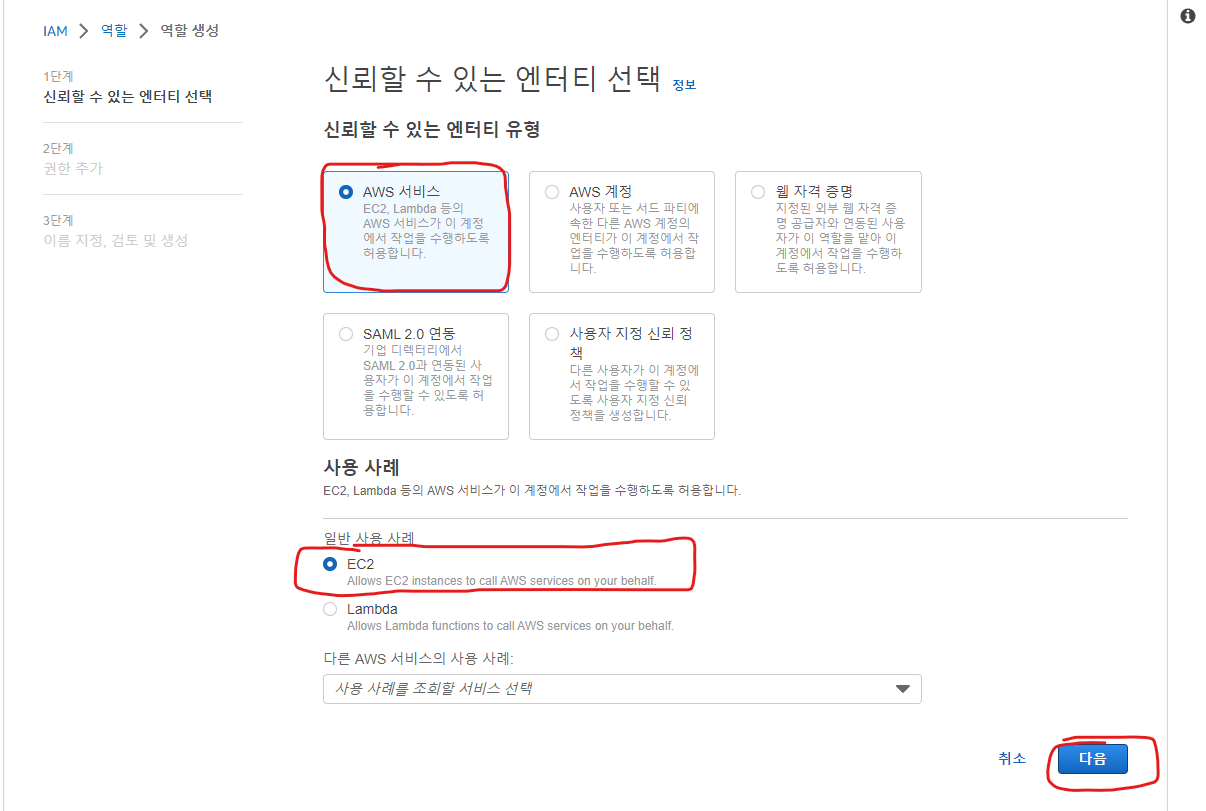
- 웹 자격 증명 또는 OIDC를 위한 역할 생성
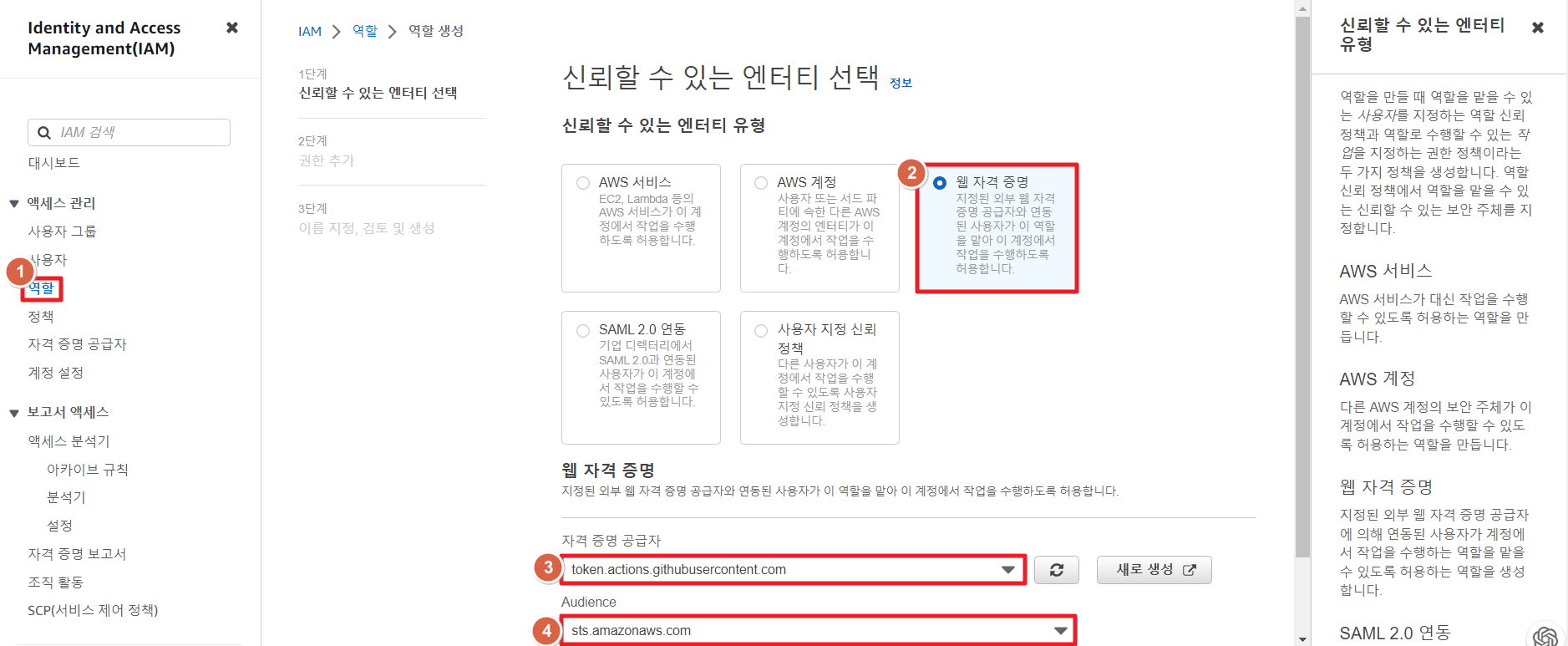
- 탐색 창에서 역할(Roles)을 선택한 후 역할 생성(Create role)을 선택
- 웹 ID(Web Identity) 역할 유형을 선택
- 자격 증명 공급자(Identity provider)에서 역할의 IdP를 선택
- Audience에서 지정한 자격증명 공급자의 대상 선택
- 권한 정책을 사용하기 위한 정책을 선택하거나 정책 생성(Create policy)을 선택하여 새 브라우저 탭을 열고 완전히 새로운 정책을 생성할 수 있음(자세한 내용은 IAM 정책 생성 섹션을 참조)
- 웹 ID 사용자에게 부여하려는 권한 정책 옆의 확인란을 선택 원할 경우, 여기서 정책을 선택하지 않고 나중에 정책을 만들어서 역할에 연결할 수 있음 (기본적으로 역할은 권한이 없음)
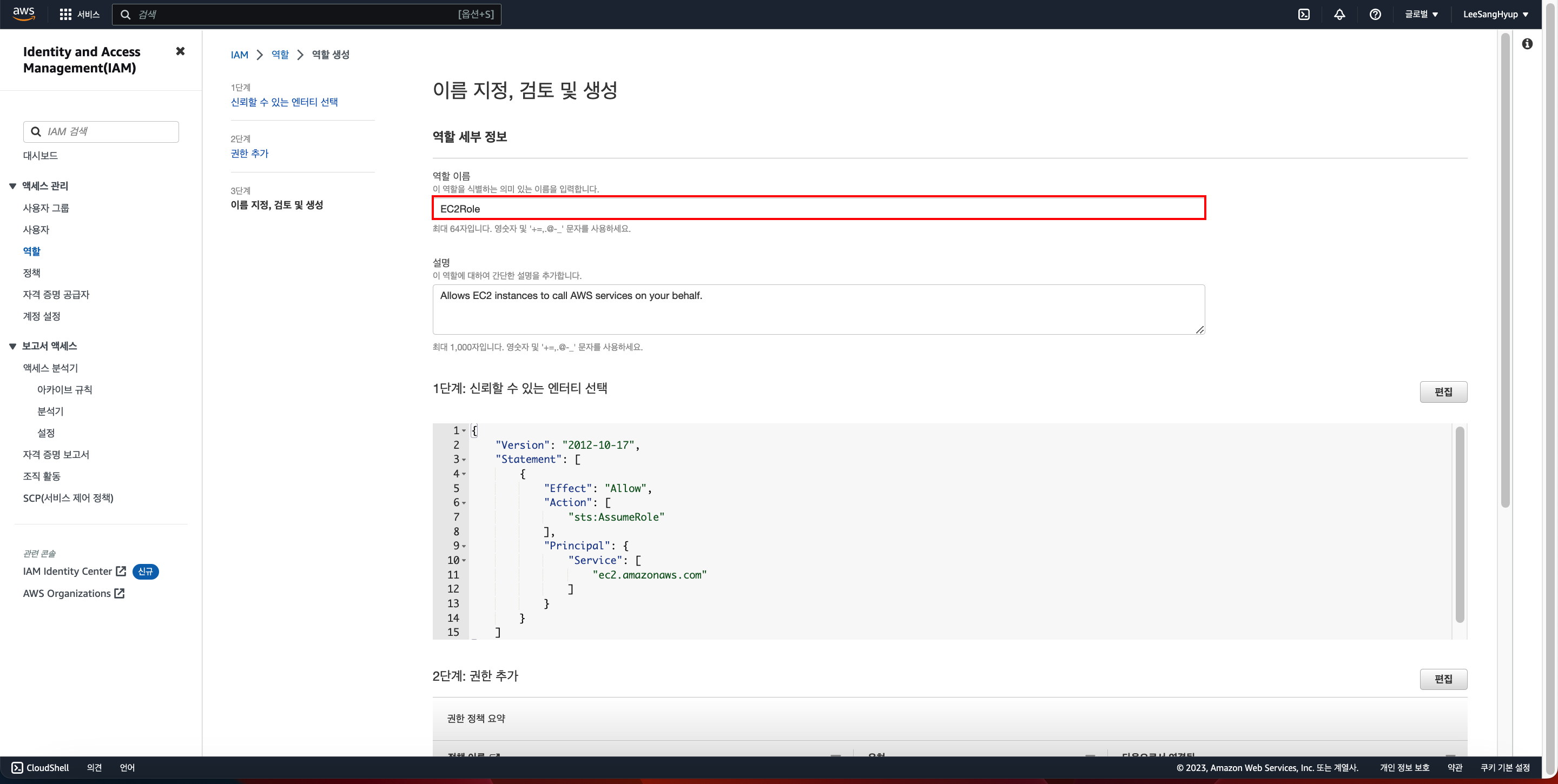
- 역할 이름(Role name)에 역할 이름을 입력
- 역할 이름은 AWS 계정 내에서 고유해야하며 대소문자를 구분하지 않음
- 다른 AWS 리소스가 역할을 참조할 수 있기 때문에 역할을 생성한 후에는 역할 이름을 편집할 수 없음
- 역할에 대한 사용 사례와 권한을 편집하려면 1단계: 신뢰할 수 있는 엔터티 선택(Step 1: Select trusted entities) 또는 2단계: 권한 추가(Step 2: Add permissions) 섹션에서 편집(Edit)을 선택
- 역할을 검토한 다음 [Create role]을 선택
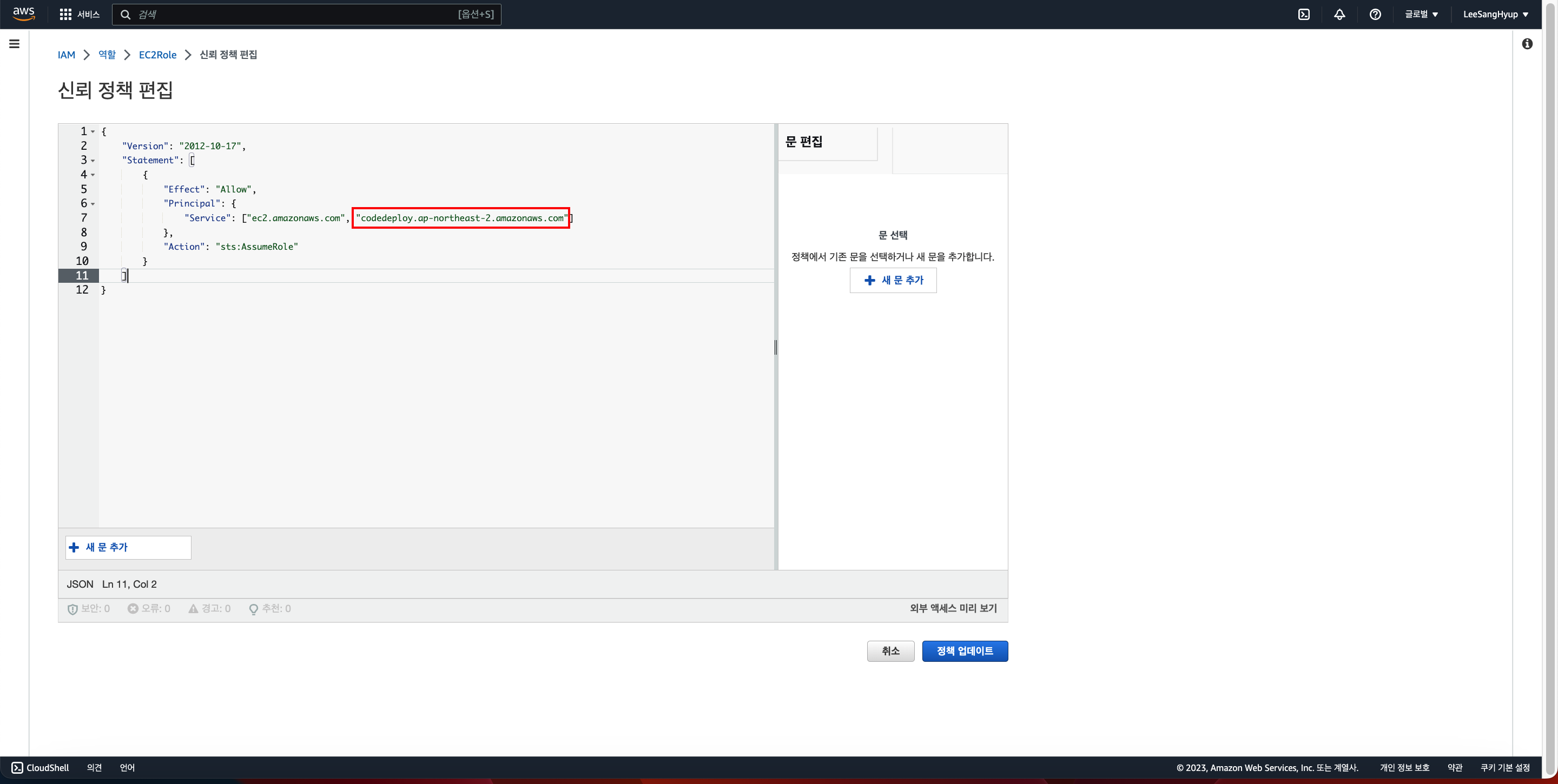
- GitHub OIDC ID 제공자의 역할 구성
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": { # OIDC Role ARN
"Federated": "arn:aws:iam::123456123456:oidc-provider/token.actions.githubusercontent.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringLike": {
"token.actions.githubusercontent.com:sub": "repo:<GitHub 조직명>/<레파지토리명>:*"
},
"StringEquals": {
"token.actions.githubusercontent.com:aud": "sts.amazonaws.com"
}
}
}
]
}
- ECR 로그인을 위한 권한 부여
4-1. ECR Private에 로그인하기 위한 최소 권한 집합
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GetAuthorizationToken",
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken"
],
"Resource": "*"
}
]
}
4-2. ECR 프라이빗 리포지토리에서 이미지를 가져오기 위한 최소 권한
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowPull",
"Effect": "Allow",
"Action": [
"ecr:BatchGetImage",
"ecr:GetDownloadUrlForLayer"
],
"Resource": "arn:aws:ecr:<리전>:<AWS 계정 ID>:repository/<레파지토리명>"
}
]
}
4-3. ECR 프라이빗 리포지토리에서 이미지를 푸시하고 풀링하기 위한 최소 권한
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowPushPull",
"Effect": "Allow",
"Action": [
"ecr:BatchGetImage",
"ecr:BatchCheckLayerAvailability",
"ecr:CompleteLayerUpload",
"ecr:GetDownloadUrlForLayer",
"ecr:InitiateLayerUpload",
"ecr:PutImage",
"ecr:UploadLayerPart"
],
"Resource": "arn:aws:ecr:<리전>:<AWS 계정 ID>:repository/<레파지토리명>"
}
]
}
📝 문제 2 : 빌드 후 ECR에 이미지가 배포되었을 때 자동으로 서비스에 배포하는 workflow 실행 시 ECR 배포 실패
- 원인 : 작업 정의 접근 권한 문제로 배포 자동화를 실패했다.
- 해결 방안 : IAM의 역할에 필요한 권한을 부여했다.
- 참고자료
{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"RegisterTaskDefinition",
"Effect":"Allow",
"Action":[
"ecs:RegisterTaskDefinition"
],
"Resource":"*"
},
{
"Sid":"PassRolesInTaskDefinition",
"Effect":"Allow",
"Action":[
"iam:PassRole"
],
"Resource":[
"arn:aws:iam::<aws_account_id>:role/<task_definition_task_role_name>",
"arn:aws:iam::<aws_account_id>:role/<task_definition_task_execution_role_name>"
]
},
{
"Sid":"DeployService",
"Effect":"Allow",
"Action":[
"ecs:UpdateService",
"ecs:DescribeServices"
],
"Resource":[
"arn:aws:ecs:<region>:<aws_account_id>:service/<cluster_name>/<service_name>"
]
}
]
}
📝 문제 3 : 컨테이너로 WAS와 DB를 따로 기동 후 WAS에서 DB 접근 불가
- 원인
- compose로 함께 기동하지 않고 따로 기동할 경우 브릿지가 생성되지 않았다.
- container는 독립된 네트워크로 동작하므로 두 서버가 동일한 서브넷에 속해있지 않았기 때문에 애초에 통신이 불가능했다.
$ docker run --name servertest -p 3000:3000 --env MONGO_PASSWORD=secret --env MONGO_HOSTNAME=172.22.0.2 --env MONGO_USERNAME=root --network devops-04-s2-team9_default ohrory218/helloworld:1.1
> helloworld-was@1.0.0 start
> fastify start -l info app.js --address 0.0.0.0
[INFO] app.js file processing
[INFO] app.js file done
[DB CONNECTION STRING] mongodb://root:secret@172.22.0.2:27017/?authMechanism=DEFAULT
MongoServerSelectionError: connect ECONNREFUSED 172.22.0.2:27017
at Timeout._onTimeout (/app/node_modules/@fastify/mongodb/node_modules/mongodb/lib/sdam/topology.js:277:38)
at listOnTimeout (node:internal/timers:569:17)
at process.processTimers (node:internal/timers:512:7) {
reason: TopologyDescription {
type: 'Unknown',
servers: Map(1) { '172.22.0.2:27017' => [ServerDescription] },
stale: false,
compatible: true,
heartbeatFrequencyMS: 10000,
localThresholdMS: 15,
setName: null,
maxElectionId: null,
maxSetVersion: null,
commonWireVersion: 0,
logicalSessionTimeoutMinutes: null
},
code: undefined,
[Symbol(errorLabels)]: Set(0) {}
}
- 트러블 슈팅
- 기동된 mongodb 컨테이너 네트워크를 확인해서 환경 변수의 HOSTNAME에 IP주소를, network에 networks명을 집어넣는다.
$ docker container inspect mongodb
[
{
#... 중략 ...#
"Networks": {
"devops-04-s2-team9_default": {
"IPAMConfig": null,
"Links": null,
"Aliases": [
"mongodb",
"mongo",
"223966663fe2"
],
# ... 중략 ....#
"IPAddress": "172.22.0.2",
# ... 하략 ....#
}
}
}
}
]
- 해결 방법
- mongo DB의 config를 변경해 외부 네트워크에서 접근 가능하도록 설정
- (채택) WAS 컨테이너를 실행할 때 DB 컨테이너가 실행된 네트워크에서 실행되도록 수정
$ docker run --name servertest -p 3000:3000 --env MONGO_PASSWORD=secret --env MONGO_HOSTNAME=172.22.0.2 --env MONGO_USERNAME=root --network devops-04-s2-team9_default ohrory218/helloworld:1.1
> helloworld-was@1.0.0 start
> fastify start -l info app.js --address 0.0.0.0
[INFO] app.js file processing
[INFO] app.js file done
[DB CONNECTION STRING] mongodb://root:secret@172.22.0.2:27017/?authMechanism=DEFAULT
{"level":30,"time":1682772429521,"pid":18,"hostname":"87140ace8e46","msg":"Server listening at http://0.0.0.0:3000"}
📝 문제 4 : 웹 서버 자동화 파이프라인 구성 시 Source에서 권한 부족 문제 발생

The provided role cannot be assumed: 'Access denied when attempting to assume the role 'arn:aws:iam::123456789012:role/service-role/AWSCodePipelineServiceRole-ap-northeast-2-helloworld-web''
- 원인 : S3 버킷에 대한 파이프라인 서비스 롤(IAM)을 사용해 AWS 리소스에 대해 액세스할 수 있는 권한 정책이 존재하지 않았다.
- 참고자료
- 해결 방안 : 해당 IAM 정책에서 사용자가 위임하려는 역할에 대해 sts:AssumeRole을 호출할 수 있는 권한을 부여해줬다.