이번프로젝트에서는 팀장으로서 팀이 프로젝트를 성공적으로 마무리 할 수 있도록 어떤 순서로 작업을 하고, 인원배분은 또 어떻게 해야할지에 대해서 많은 고민을 했다.
공동 작업
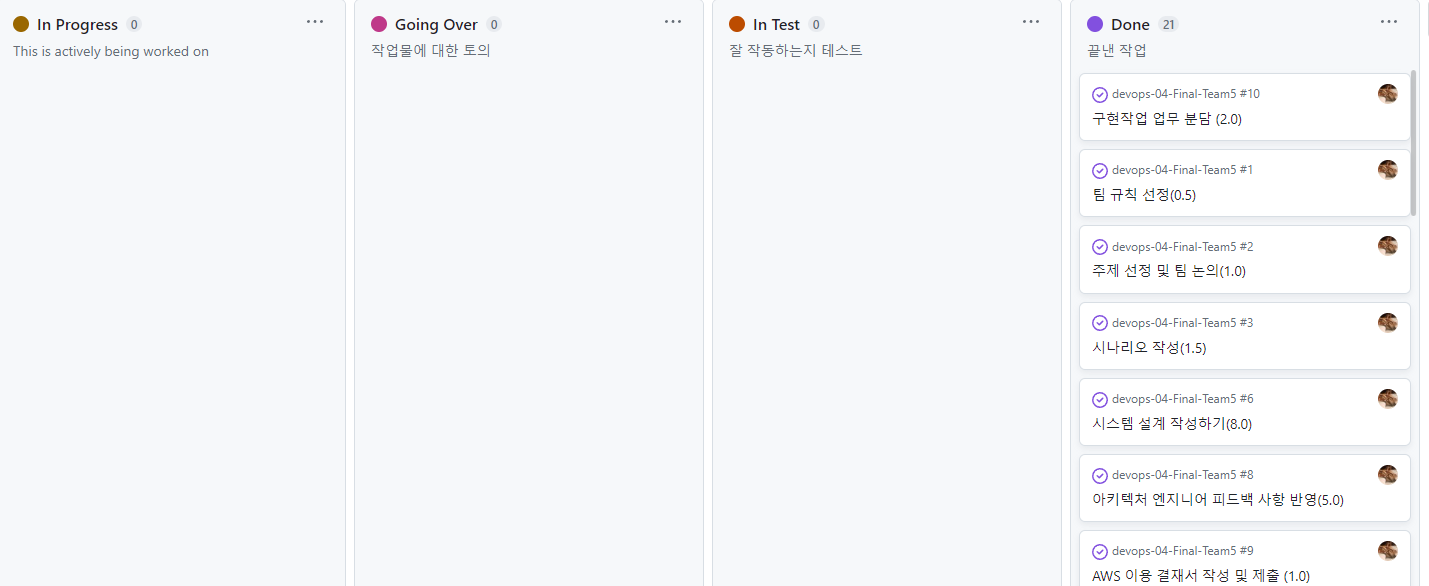
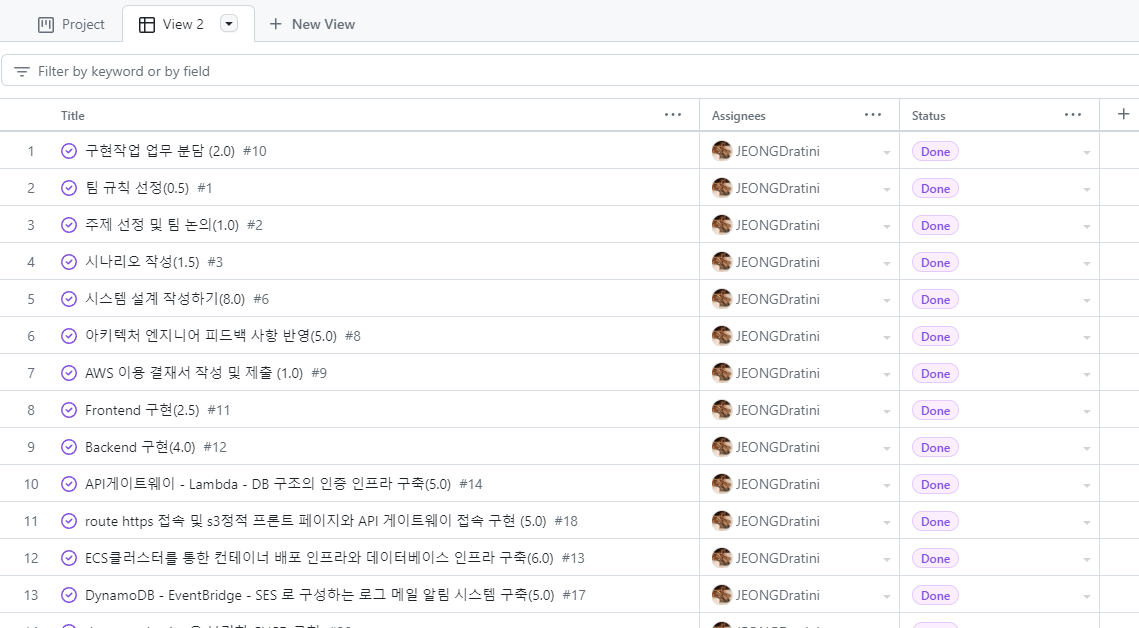
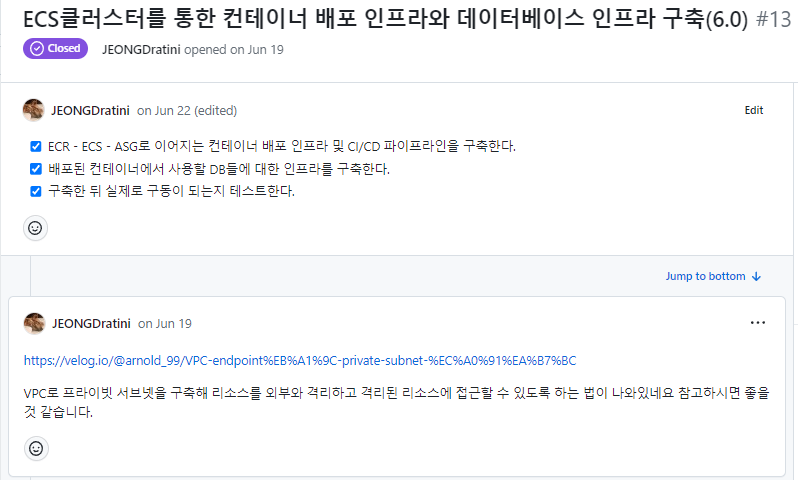
여러명이서 함께하는 팀 프로젝트인 만큼 작업내용을 구체화해서 작업시간과 인원을 배분하면 좋겠다고 생각했고, 이렇게 구체화한 작업들을 관리하기 위해서 칸반보드를 사용해서 현재 프로젝트의 진행상황이 어떤지, 작업 중에 어떤 문제를 마주쳤고 어떻게 해결했는지 확실하게 남기고자 했다.
칸반보드칸반보드를 통해 관리한 이슈들 목록
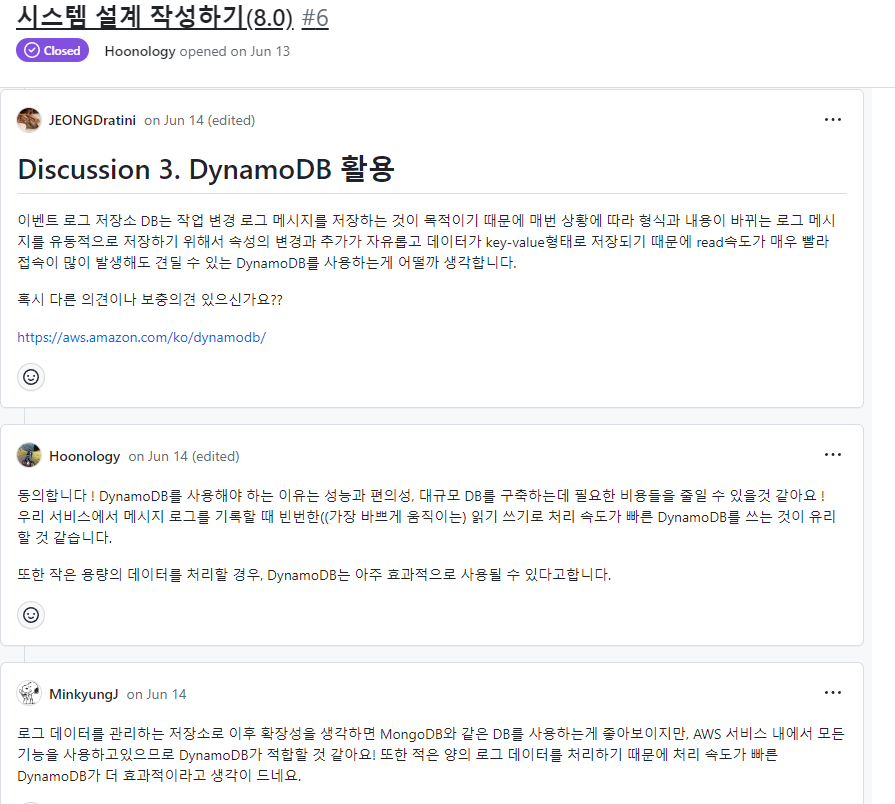
팀 규칙, 주제 선정, 시스템 설계 작성 등 프로젝트 진행에 대해 전체적인 방향성 해결해야할 문제에는 팀원 모두가 함께 머리를 맞대 최대한 빠르게 합리적인 결론을 도출하고자했다. 그리고 아래처럼 토의의 내용과 결과를 issue 탭에 기록해 issue 탭에 기록한 내용을 바탕으로 프로젝트의 다음단계를 진행했다.
시스템 리소스 설계 중 토의내용 일부발췌
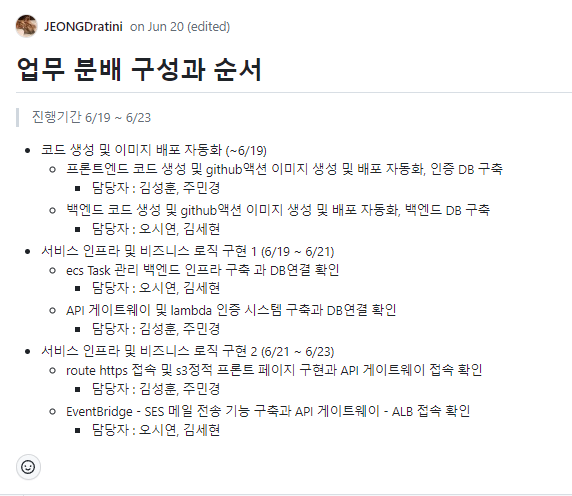
업무 분배 및 순서 토의내용 일부발췌
실제 구현파트의 작업분배는 팀원들 각각의 강점을 고려해서 분배했고, 나는 POC로서 각 일정들이 제시간에 마무리 될 수 있도록 각 파트를 오가며 작업상황을 체크하고 작업을 도와서 최대한 빨리 작업을 마무리할 수 있게끔 하는 역할을 맡았다.
이땐 알지 못했다..ㅠ 작업파트를 정하지 않았다는 것이 얼마나 많은 노동을 의미하는지...
파트 분배 작업
각자 파트를 나눠 작업해야하는 구간에서는 각 파트의 진행사항을 확인하고, 작업을 도왔다. 그래서 프론트 부분의 로직과 인프라, 백엔드 부분의 로직과 인프라 작업 모두에 참여했다.
그리고 진행상황을 최대한 쉽게 파악하기 위해 각 파트에서 해야할 일의 프로세스를 정해서 체크리스트로 만들었다.
이슈 탭 진행상황 체크리스트
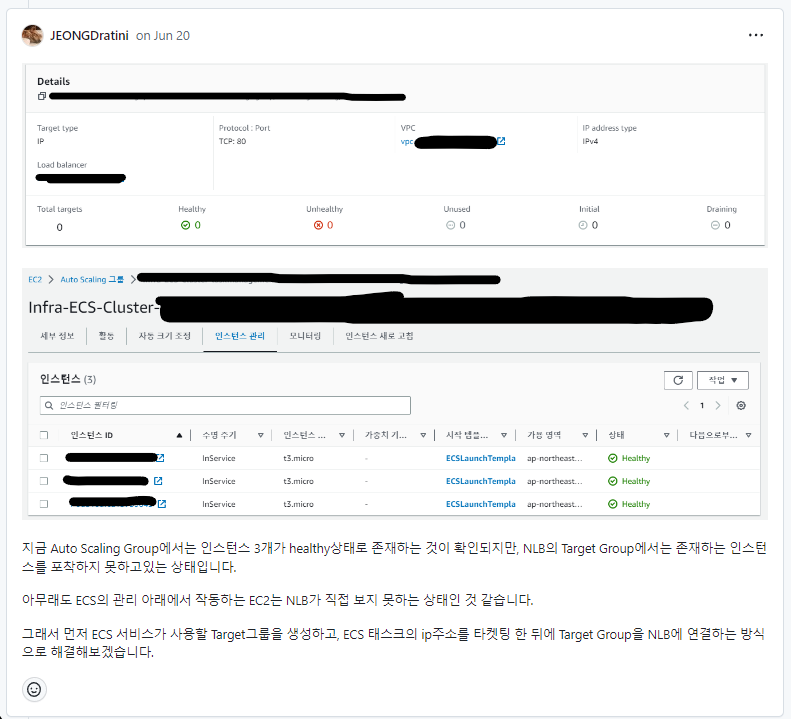
물론 작업 중에 이슈를 마주쳤을 때 아래처럼 해당 이슈에 대한 기록도 남겨 내가 어떤문제를 마주했고 어떻게 해결했는지 팀원들도 알 수 있도록 했다.
해당 문서는 vpc엔드포인트를 통해 VPC내부의 ec2가 외부의 Dynamodb 와 상호작용할 수 있도록 설정하는 법에 대해서 설명한 문서인데, 문서에서 안내해준대로 VPC 엔드 포인트를 통해 DynamoDB에 엑세스할 수 있도록 설정했더니 문제없이 아래처럼 EC2가 DynamoDB에 아이템을 집어넣는 것을 확인할 수 있었다.
Issue .6) 도메인 트래픽 API Gateway 접근 거부
API Gateway의 CORS 설정에서 도메인 트래픽에 포함된 header를 거부하도록 설정해둬서 POSTMAN으로 접속시에는 원활하게 작동하는 API가 도메인을 웹브라우저로 접속하면 접속이 되지않는 현상을 발견했다.
웹브라우저가 요청에서 어떤 header가 포함되어 요청 메시지를 보내는지 확인하고, CORS에서 해당 헤더에 대한 허가 정책을 설정해주니 API Gateway가 잘 작동하는 모습을 확인할 수 있었다.
리소스 구현을 진행하며 느낀 점
아키텍처 컨셉을 증명하는 작업. 즉, 클라우드 리소스들을 만드는 작업을 진행하면서 이 클라우드 리소스에서 작업을 할때 어떤 점을 신경써줘야하는가에 대해서 감을 잡을 수 있었다.
물론 AWS 클라우드 서비스의 종류는 아주아주 다양하고, 각 서비스들에 대해서 이해를 잘 하고있어야 제대로 사용할 수 있기 때문에 배우면 배워갈 수록 내가 점점 더 작아져보이는 듯한 기분이 든다..ㅎ
그래도 하나하나씩 배우다보면 언젠가는 클라우드 서비스들을 자유롭게 엮어서 강력한 아키텍처를 구성할 수 있는 참된 엔지니어가 될 수 있을거라고 믿어 의심하지 않는다.
name: Deploy to Amazon ECS
on:
push:
branches: [ "dev" ]
paths:
- 'Task/**'
env:
AWS_REGION: [region]
ECR_REPOSITORY: [ECR Repository name]
ECR_BACKUP_REPOSITORY: [ECR Repository name]
ECS_SERVICE:[ECS Service name]
ECS_CLUSTER: [ECS Cluster name]
CONTAINER_NAME: [ECS Container name]
permissions:
contents: read
jobs:
deploy:
name: Deploy
runs-on: ubuntu-latest
env:
working-directory: "./Task"
steps:
- name: Checkout
uses: actions/checkout@v3
# AWS 인증하기
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ env.AWS_REGION }}
# ECR에 로그인하기
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1
#각 빌드된 이미지들에게 고유한 태그(github.sha값)를 달아 ECR에 푸시
- name: Build, Unique tag, and push image to Amazon ECR
id: build-unique-image
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
IMAGE_TAG: ${{ github.sha }}
run: |
# Build a docker container and
# push it to ECR so that it can
# be deployed to ECS.
docker build -t $ECR_REGISTRY/$ECR_BACKUP_REPOSITORY:$IMAGE_TAG .
docker push $ECR_REGISTRY/$ECR_BACKUP_REPOSITORY:$IMAGE_TAG
echo "image=$ECR_REGISTRY/$ECR_BACKUP_REPOSITORY:$IMAGE_TAG" >> $GITHUB_OUTPUT
working-directory: ${{ env.working-directory }}
#latest 태그를 달아 ECR에 푸시한다. 푸시되는 레포지토리는 각각 다르다.
- name: Build, latest tag, and push image to Amazon ECR
id: build-image
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
IMAGE_TAG: latest
run: |
# Build a docker container and
# push it to ECR so that it can
# be deployed to ECS.
docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG .
docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG
echo "image=$ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG" >> $GITHUB_OUTPUT
working-directory: ${{ env.working-directory }}
#가장 최근에 사용한 task정의 파일을 사용할 수 있도록 가져온다.
- name: Retrieve most recent ECS task definition JSON file
id: retrieve-task-def
run: |
aws ecs describe-task-definition --task-definition [task-definition family name] --query taskDefinition > task-definition.json
cat task-definition.json
echo "::set-output name=task-def-file::task-definition.json"
# $GITHUB_OUTPUT
# ECS 태스크 정의에 푸시한 ECR이미지 id를 집어넣는다.
- name: Fill in the new image ID in the Amazon ECS task definition
id: task-def
uses: aws-actions/amazon-ecs-render-task-definition@v1
with:
task-definition: ${{ steps.retrieve-task-def.outputs.task-def-file }}
container-name: ${{ env.CONTAINER_NAME }}
image: ${{ steps.build-image.outputs.image }}
# ECS 태스크 정의를 배포한다.
- name: Deploy Amazon ECS task definition
uses: aws-actions/amazon-ecs-deploy-task-definition@v1
with:
task-definition: ${{ steps.task-def.outputs.task-definition }}
service: ${{ env.ECS_SERVICE }}
cluster: ${{ env.ECS_CLUSTER }}
wait-for-service-stability: true
이미지를 푸시할 ECR 이미지를 2개로 나눈 이유
우린 ECR에 이미지를 푸시한 후 배포할 때, latest태그가 붙어있는 이미지를 배포하는 것으로 aws.json의 태스크 정의 파일을 작성했다.
그런데 ECR 레포지토리에 푸시된 이미지를 보니 가장 최근에 배포된 latest태그가 붙어있는 이미지를 제외하고 나머지 이미지들은 태그가 붙어있지 않고있다는 것을 확인해 각 배포되는 이미지에 Unique한 값을 가진 태그를 붙여 서로 구별이 가능하고 만약의 경우에 태그를 지정해서 이미지 작업을 할 수 있도록 했다.
그리고 task.json파일에는 aws리소스의 주소같은 크리티컬한 정보들이 담겨있기 때문에 민감한 정보들의 노출을 최소화하기 위해서 가장 최근에 사용했던 task.json파일을 사용해서 인프라를 배포하도록 코드를 작성했다.
Lambda 이미지 배포 yaml 코드
name: Deploy to Auth Lambda
on:
push:
branches: [ "dev" ]
paths:
- 'Auth/**'
jobs:
deploy:
runs-on: ubuntu-latest
env:
working-directory: "./Auth"
steps:
- name: Checkout
uses: actions/checkout@v3 # 최신 소스 코드를 체크아웃합니다.
- name: Set up Node.js
uses: actions/setup-node@v2
with:
node-version: 14 # 사용할 Node.js 버전을 지정합니다.
- name: Install dependencies
run: npm ci # 필요한 의존성을 설치합니다.
- name: Package Function
run: zip -r function.zip * # 필요한 파일들을 압축합니다.
working-directory: ${{ env.working-directory }}
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} # AWS_ACCESS_KEY_ID를 GitHub Secrets에서 가져옵니다.
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} # AWS_SECRET_ACCESS_KEY를 GitHub Secrets에서 가져옵니다.
aws-region: ap-northeast-2 # AWS region을 지정합니다.
- name: Deploy to Lambda
run: aws lambda update-function-code --function-name <람다 함수 이름> --zip-file fileb://function.zip # Lambda 함수 이름
working-directory: ${{ env.working-directory }}
CI/CD 파이프라인을 만들면서 개발을 하면서 실제 리소스에서도 잘 돌아가는지 테스트하기 위한 dev브랜치와 진짜 서비스 제공을 위해서 배포하기 위한 버전 코드가 올라가는 main브랜치로 구분해서 CI/CD를 구현하려고 했습니다. dev브랜치 CI/CD가 배포하는 리소스와 main 브랜치 CI/CD가 배포하는 리소스를 구분해서 배포할 수 있다면 확실하게 개발과 프로덕션 파트를 분리할 수 있을 것이라고 생각한다.
CI/CD 파이프라인 구현을 진행하며
CI/CD파이프라인 구현을 진행하면서 단순히 깃헙에 올라온 코드를 클라우드 리소스 상에 배포하는 것 뿐만 아니라, 개발 - 프로덕션의 단계를 구분해서 배포를 하기위해서는 어떻게 하는 것이 좋을까 제대로 고민해볼 수 있었던 시간이었다.
그리고 한번은 이상한 코드가 dev브랜치의 Front디렉토리 안으로 push되어 배포까지 진행돼버려서 Route53도메인으로 접속했을 때 요상한 화면이 출력된 적이 있는데, 만일 production와 dev의 구분없이 단일 브랜치로 레포지토리 구성을 했다면 production단계에서 앞서 말한 것 같은 끔찍한 일이 생겼을 것이다.
그래서 dev - production을 구분해서 작업하는 것이 굉장히 중요하다는 것을 느꼈고, 어떻게 하면 잘 구분해서 사용할 수 있을지 앞으로도 더 고민해봐야할 숙제다.
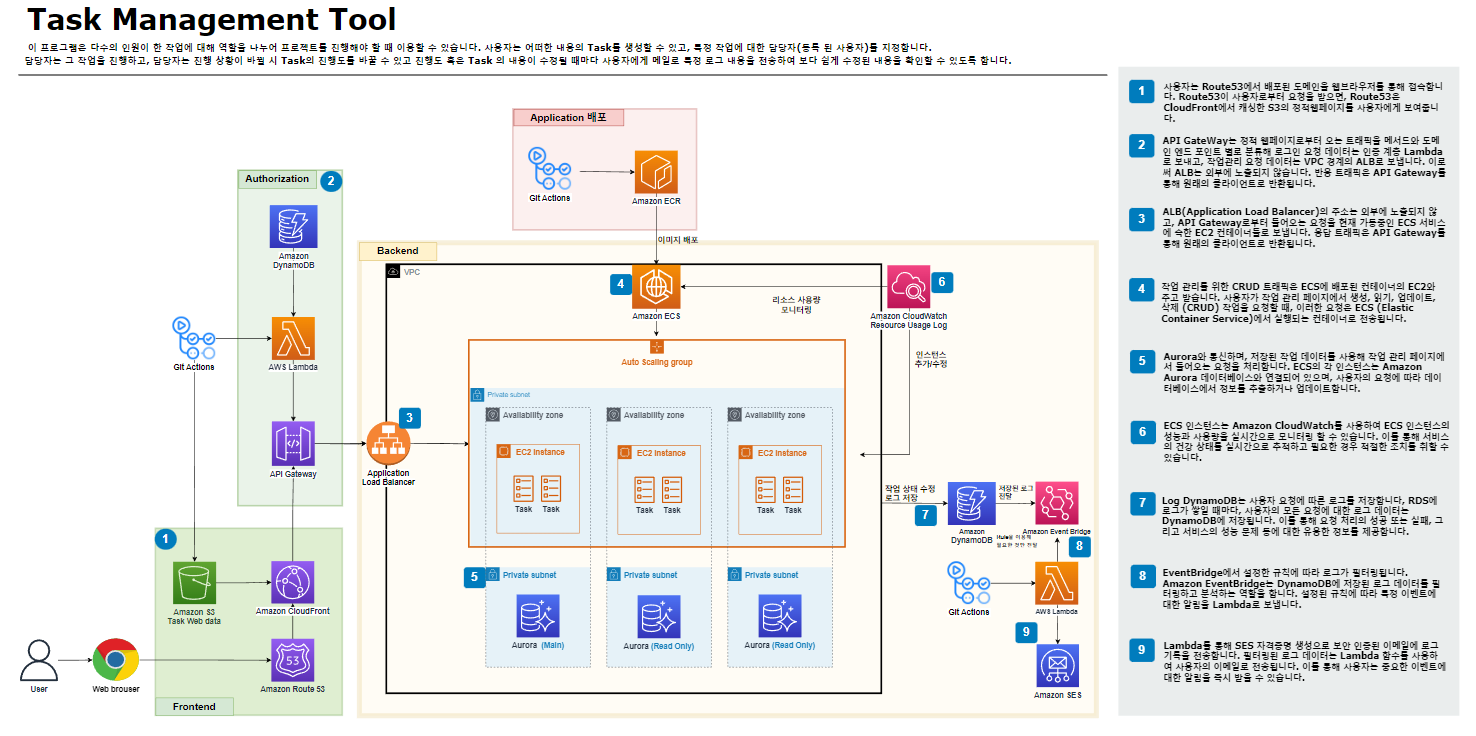
1. 먼저 사용자는 Route53에서 배포된 도메인을 웹브라우저를 통해 접속한다. Route53이 사용자로부터 요청을 받으면, Route53은 CloudFront에서 캐싱한 S3의 정적웹페이지를 사용자에게 보여준다.
2. API GateWay는 정적 웹페이지로부터 오는 트래픽을 메서드와 도메인 엔드 포인트 별로 분류해 로그인 요청 데이터는 인증 계층 Lambda로 보내고, 작업관리 요청 데이터는 VPC 경계의 ALB로 보낸다.
이로써 ALB는 외부에 노출되지 않습니다. 반응 트래픽은 API Gateway를 통해 원래의 클라이언트로
반환된다.
3. ALB(Application Load Balancer)의 주소는 외부에 노출되지 않고, API Gateway로부터 들어오는 요청을 현재 가동중인 ECS 서비스에 속한 EC2 컨테이너들로 보낸다. 응답 트래픽은 API Gateway를 통해 원래의 클라이언트로 반환된다.
4. 작업 관리를 위한 CRUD 트래픽은 ECS에 배포된 컨테이너의 EC2와 주고 받는다. 사용자가 작업 관리 페이지에서 생성, 읽기, 업데이트, 삭제 (CRUD) 작업을 요청할 때, 이러한 요청은 ECS (Elastic Container Service)에서 실행되는 컨테이너로 전송된다.
5. Aurora와 통신하며, 저장된 작업 데이터를 사용해 작업 관리 페이지에서 들어오는 요청을 처리한다. ECS의 각 인스턴스는 Amazon Aurora 데이터베이스와 연결되어 있으며, 사용자의 요청에 따라 데이터베이스에서 정보를 추출하거나 업데이트한다.
6. ECS 인스턴스는 Amazon CloudWatch를 사용하여 ECS 인스턴스의 성능과 사용량을 실시간으로 모니터링 할 수 있다. 이를 통해 서비스의 건강 상태를 실시간으로 추적하고 필요한 경우 적절한 조치(ex. ASG 인스턴스 조절)를 취할 수 있도록 해준다.
7. Log DynamoDB는 사용자 요청에 따른 로그를 저장한다, Aurora에서 CRUD 작업이 처리될 때마다, 사용자의 모든 요청에 대한 작업관리 로그 데이터는 DynamoDB에 저장된다. 이를 통해 작업에 어떤 변동사항이 있는지 등에 대한 유용한 정보를 제공한다.
8. EventBridge에서 설정한 규칙에 따라 Log DynamoDB의 로그가 필터링된다. Amazon EventBridge는 Log DynamoDB에 저장된 로그 데이터를 필터링하고 분석하는 역할을 합니다. 설정된 규칙에 따라 특정 이벤트에 대한 알림을 Lambda로 보내다.
9. Lambda를 통해 SES 자격증명 생성으로 보안 인증된 이메일에 로그 기록을 전송한다. 필터링된 로그 데이터는 Lambda 함수를 사용하여 사용자의 이메일로 전송된다. 이를 통해 사용자는 중요한 이벤트에 대한 알림을 즉시 받을 수 있다.
그리고 Git Action은 GitHub 레포지토리에 push된 코드들을 자동으로 각 코드들이 배포되어야할 리소스로 배포한다. CRUD이미지는 ECS 컨테이너로, 로그인요청처리와 로그이벤트코드는 각각의 람다 함수로, 프론트 웹페이지 코드는 s3 버킷으로 배포되도록 CI/CD 파이프라인을 구성할 계획이다.
리소스 아키텍처 구상 중 토의
Issue #1
API Gateway vs Load Balancer - 리소스 아키텍처 부분에서 최대한 고가용성을 확보하기 위해 다양한 기능을 제공하는데 특화된 API Gateway 보다는, 안정적인 트래픽 분산을 시킬 수 있어 서비스 제공을 안정적으로 유지하는데에 특화된 Load Balancer를 사용하는 것에 대한 논의
Load Balancer는 트래픽 분산에 특화되어 있고, 단순성을 생각했을 때 관리가 용이하며, 비용에서도 API Gateway와 거의 차이가 없기 때문에 Load Balancer를 사용하기로 결정하였다.
Issue #2
RDS 가용성 - Multi-AZ 기능을 사용해서 이중화 DB를 구성하여 만일 기존 DB 인스턴스에 중단이 발생했을 때, 자동으로 다른 가용 영역에 있는 복제본으로 스위칭시켜 서비스를 계속 제공할 수 있도록 하는 것에 대한 논의
RDS는 다중 AZ 배포와 자동 백업, 복구 등의 기능이 보장되고, 다중 AZ를 사용하면 트래픽을 오프로드하고 성능을 향상시키는 데에 도움이 될 것이라고 생각해 RDS 이중화를 사용하려했다
물론, Aurora는 메인 DB를 Read, Write 할 수 있고 Sub DB들도 Read권한이 있어 트래픽이 분산될 뿐만 아니라 리소스의 낭비도 RDS에 비해 적기 때문에, RDS의 사용량에 따른 비용과 Aurora 비용을 비교하여 사용할 수 있다. 하지만, 프로젝트에서 사용할 수 있는 예산 문제로, Aurora 사용이 어려울 것 같아 RDS로 사용하게 되었다.
Issue #3
DynamoDB 활용 - 이벤트 로그 저장소 DB는 작업 변경 로그 메시지를 저장하는 것이 목적이기 때문에 매번 상황에 따라 형식과 내용이 바뀐다. 따라서 로그 메시지를 유동적으로 저장하기 위해 속성의 변경과 추가가 자유로운 DynamoDB를 사용하는 것이 어떨까? DynamoDB는 데이터가 key-value 형태로 저장되기 때문에 read 속도도 빨라 접속이 많이 발생해도 견딜 수 있다.
DynamoDB는 성능과 편의성에서도 용이하고, 구현할 아키텍처는 적은 양의 로그 데이터를 처리하기 때문에 처리 속도가 빠른 DynamoDB가 효과적이다. 또한 DynamoDB는 AWS Lambda와 같은 이벤트 기반 처리 시스템과 잘 통합되어 실시간 로그 분석과 같은 복잡한 로그 처리 작업 또한 쉽게 구현할 수 있게 해준다.
Issue #4
SNS + SQS vs Eventbridge - 기존에 사용해보아서 익숙한 SNS를 사용할지, 새로 접하지만 필터링 기능이 있어 이벤트 관리가 용이한 Eventbrige를 사용할지에 대한 논의
필터링 기능을 이용해 편리하게 로그를 원하는 방식으로 필터링하고 로그의 형식에 따라 원하는 이벤트를 발생시킬 수 있는 Eventbridge를 사용하기로 결정했다.
WAS => Dynamo => Lambda => Eventbridge => Rule => SES : 작업 CRUD에 대한 로그를 전부 Dynamo에 쌓을 예정이기 때문에 이 플로우 사용하기로 결정했다.
ASG (EC2) vs Fargate - Fargate도 서버리스로 구동이 되고, 리소스 사용률이 높을수록 비용 방면에서 효율이 좋지만, ASG를 이용할 시, 인프라 관리가 어렵고 운영이 복잡할 수 있다.
ECS의 컨테이너를 구동할 때 사용하는 컴퓨팅 유닛으로 EC2를 사용하는 것이 리소스 사용률이 낮을 경우에는 Fargate가 EC2보다 평균적으로 비용이 13~18% 정도 비싸고, Cloudwatch를 통해서 리소스 예약률을 90% 이상 높게 유지하도록 auto scaling을 하도록 만들면 더 비용 절감을 할 수 있다. 따라서 EC2를 이용하기로 결정했다.
엔지니어님의 조언과 요구사항을 참고해 도메인 이벤트를 붙이고 이후에 액터, 커멘드 포스트잇을 붙여서 프로젝트를 구현할 때 어떤 부분에 대해서 미리 팀원들간의 토의를 해야하는지 파악하고 기록해뒀다. 외부시스템은 사용하지 않을 것이기에 제외했고, 에그리거트와 정책으로 도메인들을 분리하고 연결했다.
그렇게 사용자의 인증을 담당하는 User Management, 작업을 관리하는 Task Management Service, 그리고 작업과 시스템의 변동사항을 기록하고 변동사항에 알맞는 알림을 보내주는 Log Mornitoring System으로 분리했다.
ERD 설계
각 분리된 서비스 별로 사용할 데이터베이스의 기술 스택을 정했다.
Log Mornitoring System와User Management 파트에서는 차후 유연성 및 분산환경에서 확장성, 내결함성을 더 잘 지원할 수 있는 NoSQL을 사용하고,
사용자로부터 가장 많은 요청을 처리해야하는Task Management Service 파트에서는 MySQL을 사용하기로 결정했다.
ERD를 작성하면서 Task에 반영되는 User 역할을 어떻게 구분할 것인가에 대한 논의를 한 결과 Task에서 Supervisor_email과 PIC_email 속성을 만들어 User table을 참조하도록 만들기로 했다.
그리고 우린 백엔드 프로젝트를 진행하는 것이 아니기 때문에 Users 테이블에는 인증을 위한 최소한의 데이터만 사용도록 했다.
기술 스택
CRUD 문서 작성
엔지니어께 CRUD 문서를 작성해 실제 구현단계에서의 실수를 방지하는 것이 좋다는 조언을 듣고, 구현할 api의 CRUD 문서를 작성했다. 문서를 팀원들과 정리하며 정말 필요한 기능이 무엇인지 생각해볼 수 있었고, 정말 필요한 기능들이 무엇인지 파악해 CRUD문서를 작성했다.
* 1. 검색 창에 EC2를 검색하여 들어간 후 EC2를 생성(EC2에 서버구동을 위한패키지 설치, 포트설정은 되어있어야한다.)*
> 작업 -> 인스턴스 설정 -> 태그 관리 클릭
태그를 생성하는 이유:
* > AWS에서 사용하는 리소스들을 태그별로 분류해 관리하기 위함(비용적, 유지보수적 측면에서 유리)*
2. 새로운 태그 추가
3. **_IAM 역할 수정_**
> 작업 -> 보안 -> IAM 역할 수정 클릭
IAM 역할 수정하는 이유:
* > 인스턴스가 다른 AWS 서비스와 통신할 때, 접근 권한을 주기 위함*
4. 새 IAM 역할 생성 클릭
5. 역할 만들기 클릭
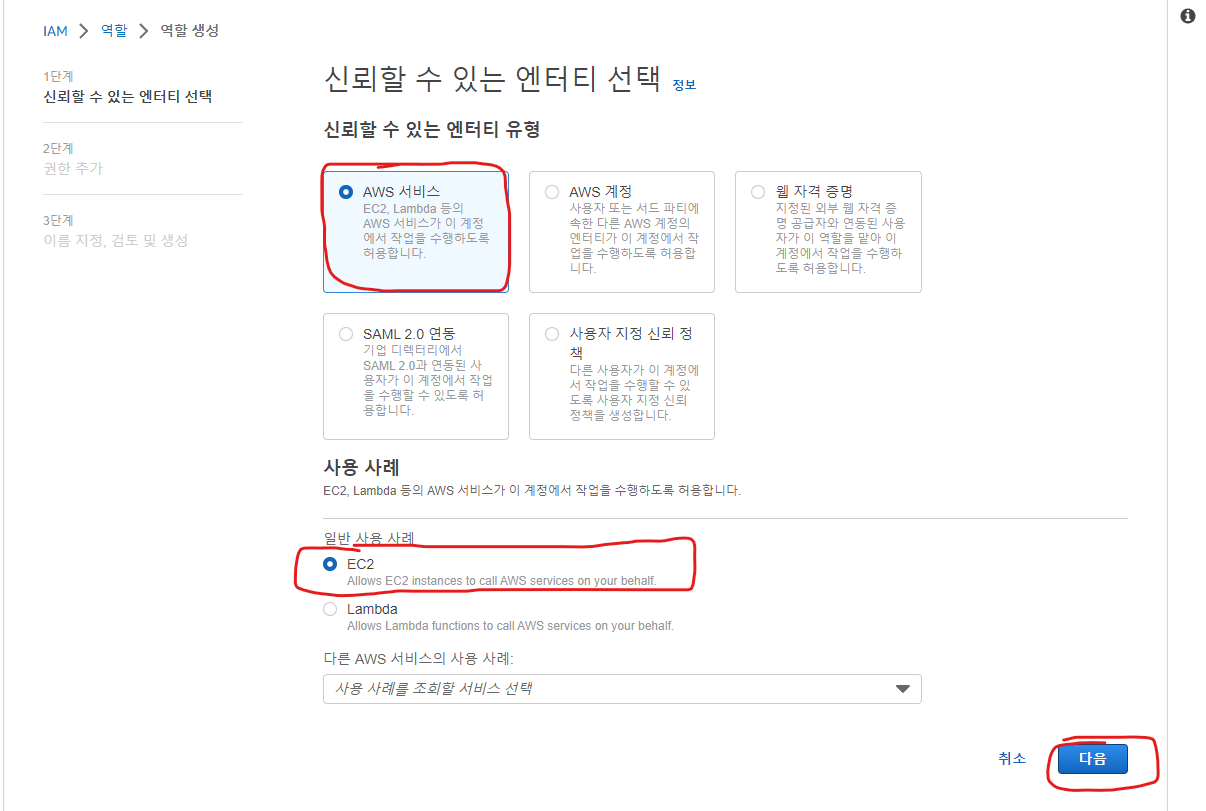
6. AWS Deploy를 이용하여 EC2에 작업할 것이므로 AWS 서비스 선택
> EC2 선택
7. CodeDeploy가 S3에 있는 코드를 사용할 것이므로 'AmazonS3 FullAcess' 선택, **_EC2에 Agent를 설치하기 위해서 'AmazonSSMFullAccess' 도 선택해준다. 그리고 마지막으로 'AWSCodeDeployRole' 까지 선택해준다._**
AWSCodeDeployRole 사용 이유
> CodeDeploy에서 배포하는 애플리케이션을 관리하는 데 필요한 권한을 제공
> CodeDeploy 배포 그룹을 만들 때 사용됩니다. 배포 그룹은 배포할 대상을 지정하는 데 사용
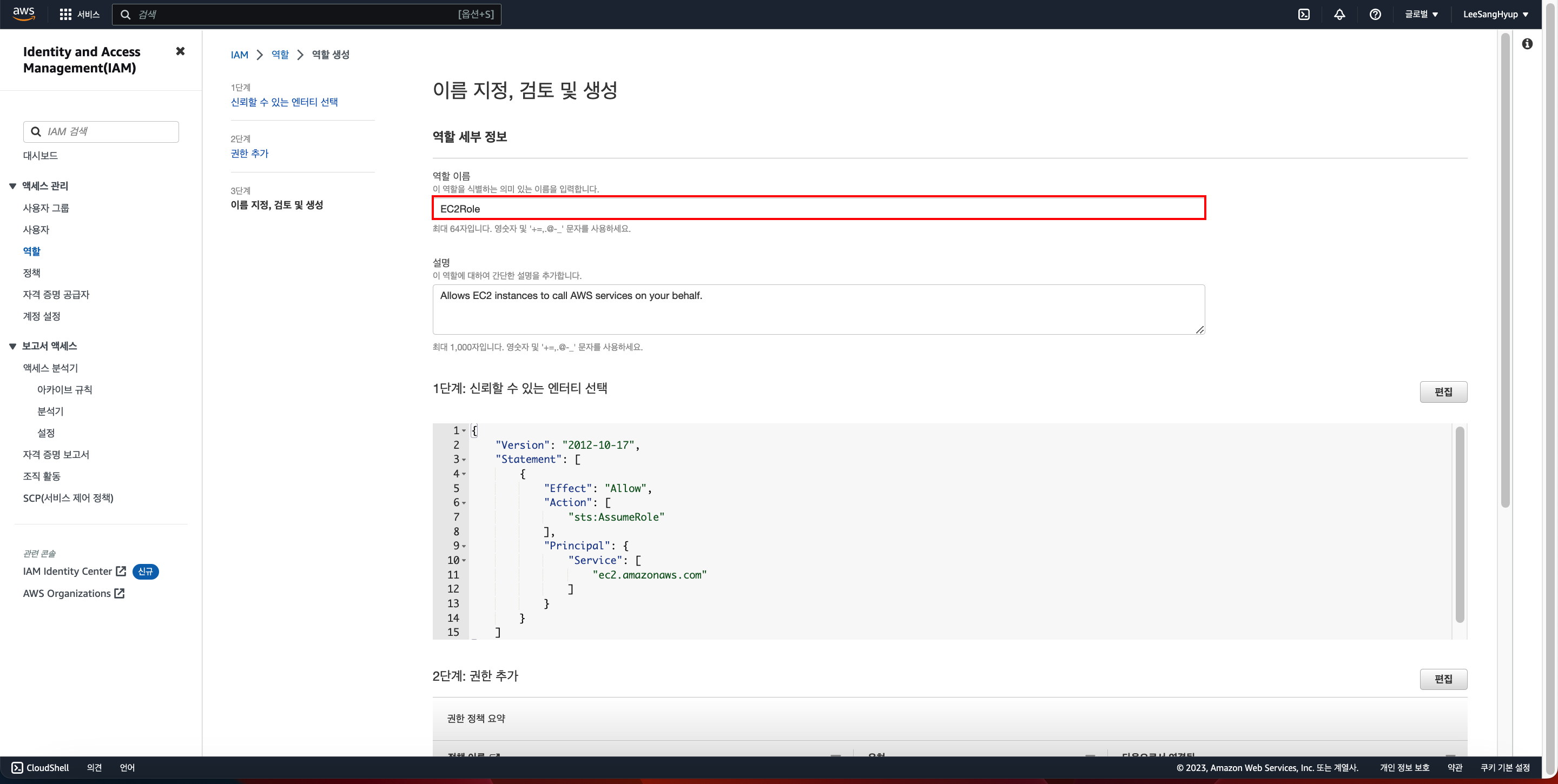
8. 역할 이름 지정하고 '역할 생성' 클릭
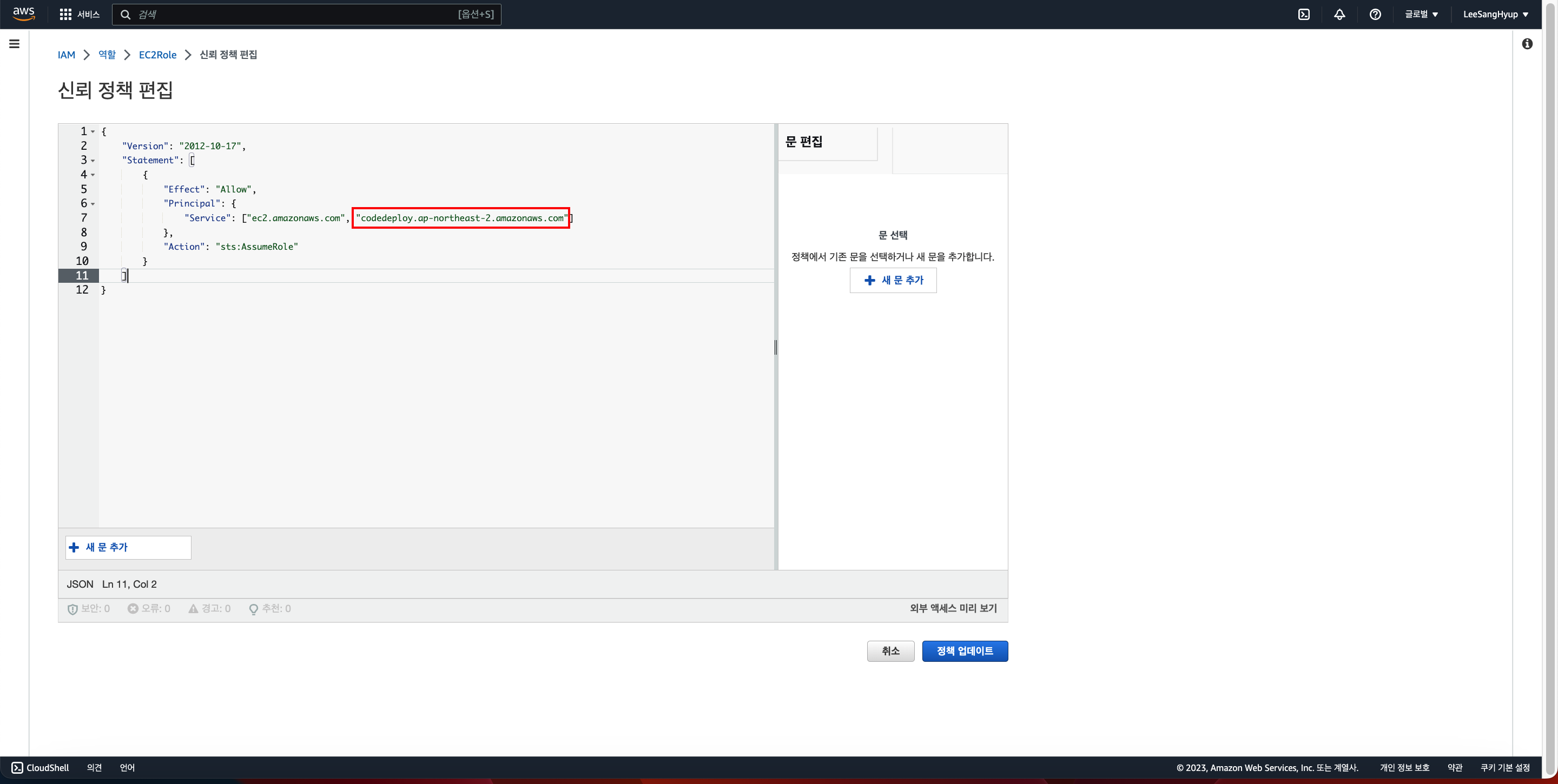
9. ec2 뿐만아니라 aws 서비스인 codedeploy도 리소스에 접근할 수 있도록 추가
10. 실습에 활용할 로컬 파일에 appspec.yml파일을 추가한다. 그리고 각 hook에 해당하는 파일들도 작성해준다.
> 소스코드의 위치를 지정하고, 각 hook에 해당하는 파일의 위치와 실행할 계정을 지정해준다.
> 배포 그룹 생성
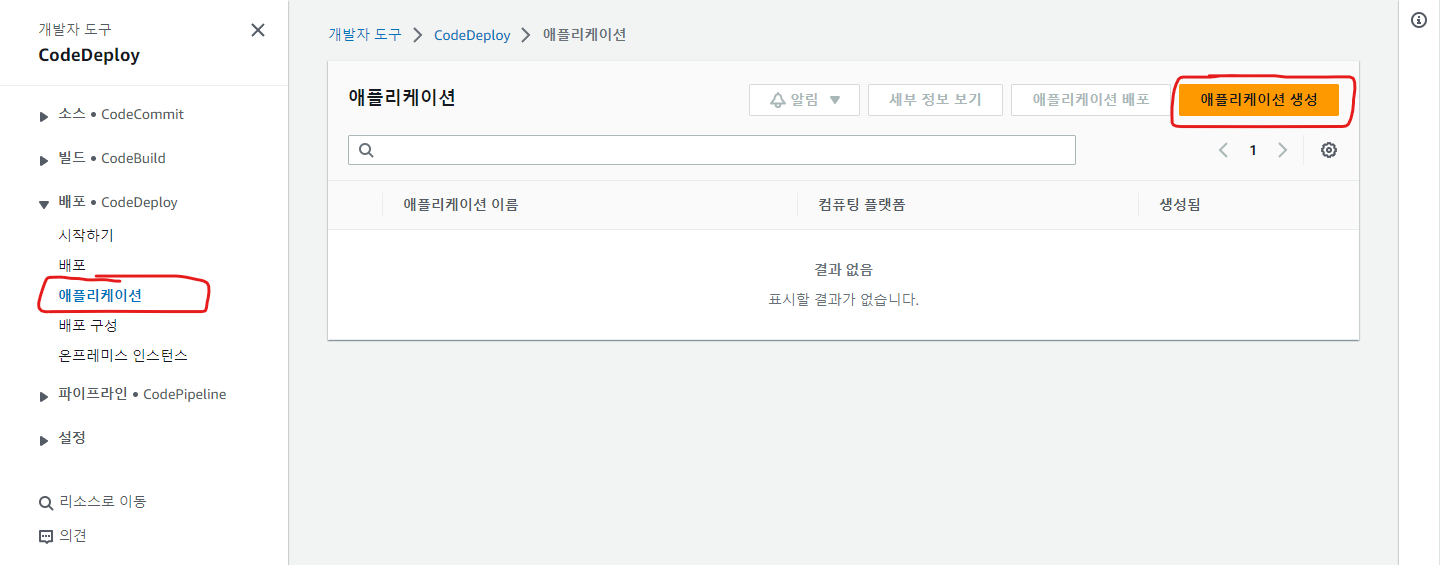
11. AWS CodeDeploy 대시보드로 이동해 애플리케이션으로 이동하고 **_[ 애플리케이션 생성 ] 버튼을 클릭_**
12. 애플리케이션의 이름을 임의로 입력하고, 컴퓨팅 플랫폼을 'EC2/온프레미스'로 선택한 뒤, [ 애플리케이션 생성 ] 버튼을 클릭
13. 애플리케이션이 생성되면, 생성한 애플리케이션의 배포 그룹 탭을 클릭하여 [ 배포 그룹 생성 ] 버튼을 클릭
14. 배포 그룹의 이름을 임의로 입력하고, 서비스 역할 영역을 클릭한 후 전에 생성했던 'EC2Role'을 선택
15. 환경 구성 중 'Amazon EC2 인스턴스'를 선택하고, 태그 그룹에 EC2 인스턴스에 설정해놓았던 태그 키와 값을 선택
16. 로드 밸런싱 활성화 체크 해제 후, [ 배포 그룹 생성 ] 버튼을 클릭
> 배포 파이프라인 생성
17. CodePipeline 대시보드로 이동 후, [ 파이프라인 생성 ] 버튼을 클릭한다. 그리고 파이프라인 이름을 임의로 입력 후, [ 다음 ] 버튼을 클릭
18. 앞서 클라이언트에서 했던 파이프라인 생성과정을 진행해주고, GitHub연결을 이미 했으므로 생성해둔 GitHub연결을 가져온다.
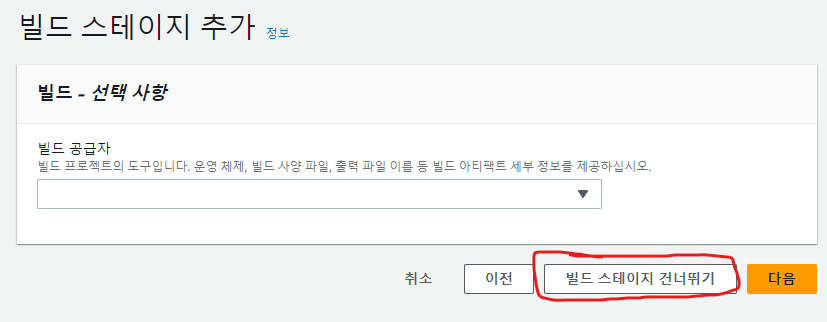
19. 우리가 이용하는 서버 코드(애플리케이션)는 코드의 컴파일과 빌드 과정이 필요 없고 테스트 코드도 없으므로, [ 빌드 스테이지 건너뛰기 ] 버튼을 눌러 빌드 단계를 생략
20. 배포 스테이지의 각 항목을 적절하게 생성해준다. 이번엔 CodeDeploy를 사용하므로 CodeDeploy를 선택해준다.
21. 잘못된 것이 있는지 확인 후 파이프라인 생성
결과
> 환경변수 설정.
환경 변수를 AWS System Manager Parameter Store에서 설정할 것이기 때문에 AWS CLI를 먼저 EC2 instance에 설치해야 한다. 밑에 명령어를 차례대로 입력
AWS CLI를 다운로드 하기 위한 명령어
AWS 버전을 확인
이렇게 되면 aws CLI는 설치가 완료된 것이다
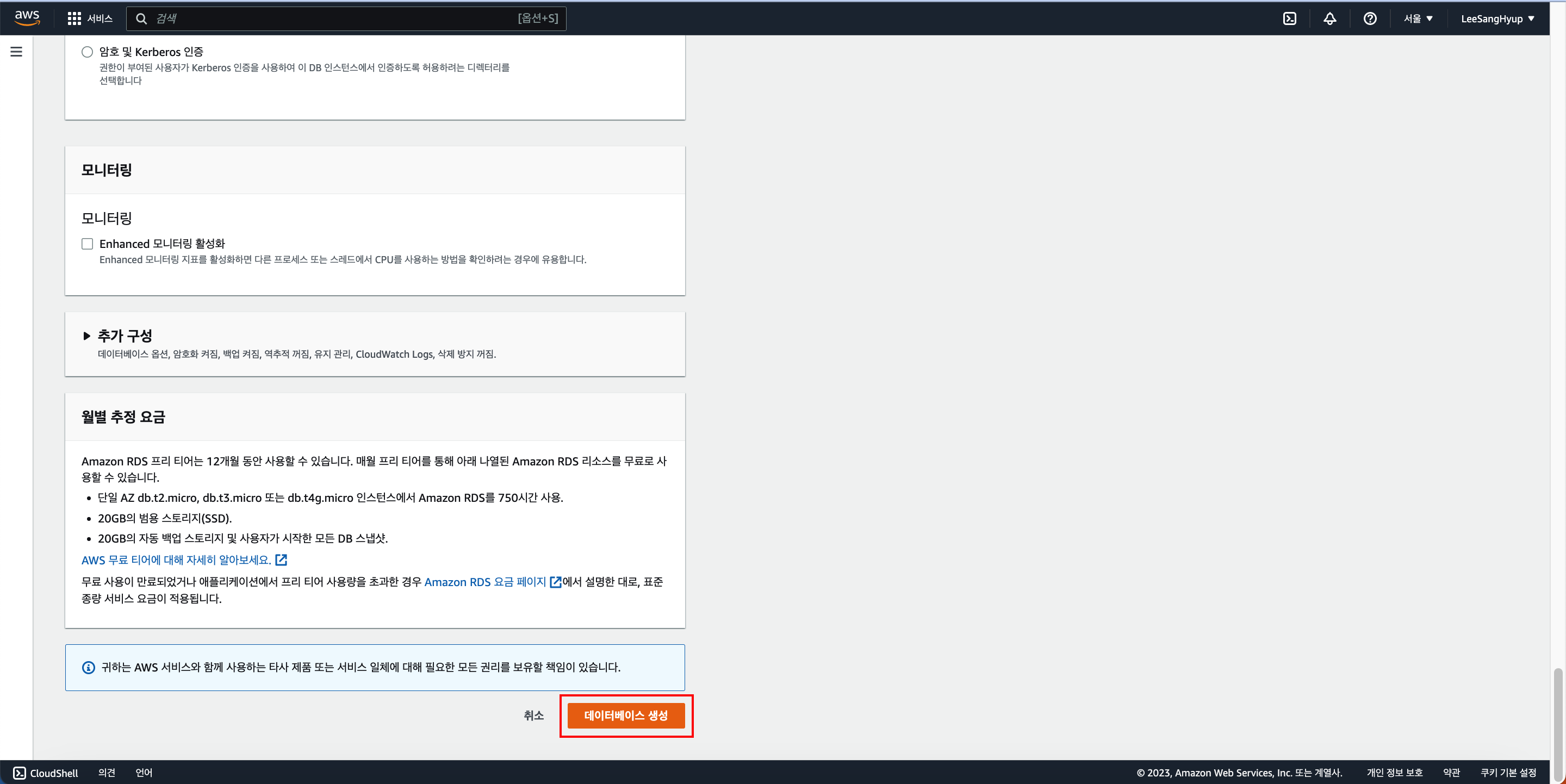
RDS 생성
검색 창에 RDS 입력 후 데이터베이스 생성을 클릭
엔진 옵션에 원하는 데이터베이스 소프트웨어를 선택
탬플릿은 사용 용도에 따라 선택하면 되는데, 비용이 제일 싼 걸 선택했다
스크롤을 내려 DB 인스턴스 식별자, 마스터 사용자 이름, 암호를 기입
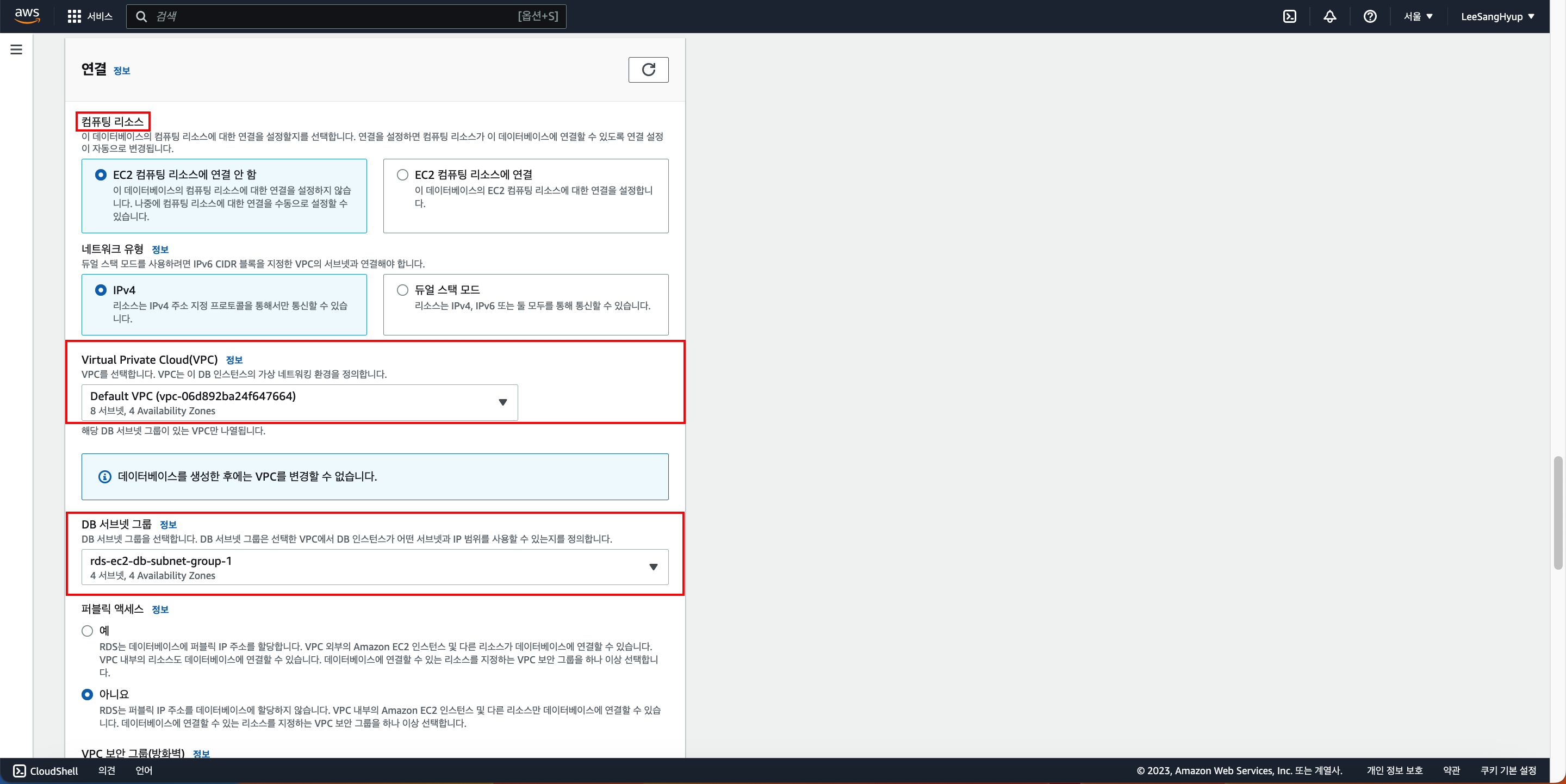
컴퓨터 리소스는 기존 EC2에 연결하고 싶으면 오른쪽을 아니면 왼쪽을 클릭
VPC는 기존 EC2 VPC에 연결할 수 있음
DB 서브넷 그룹도 기존 존재하던 것에 연결할 수 있음
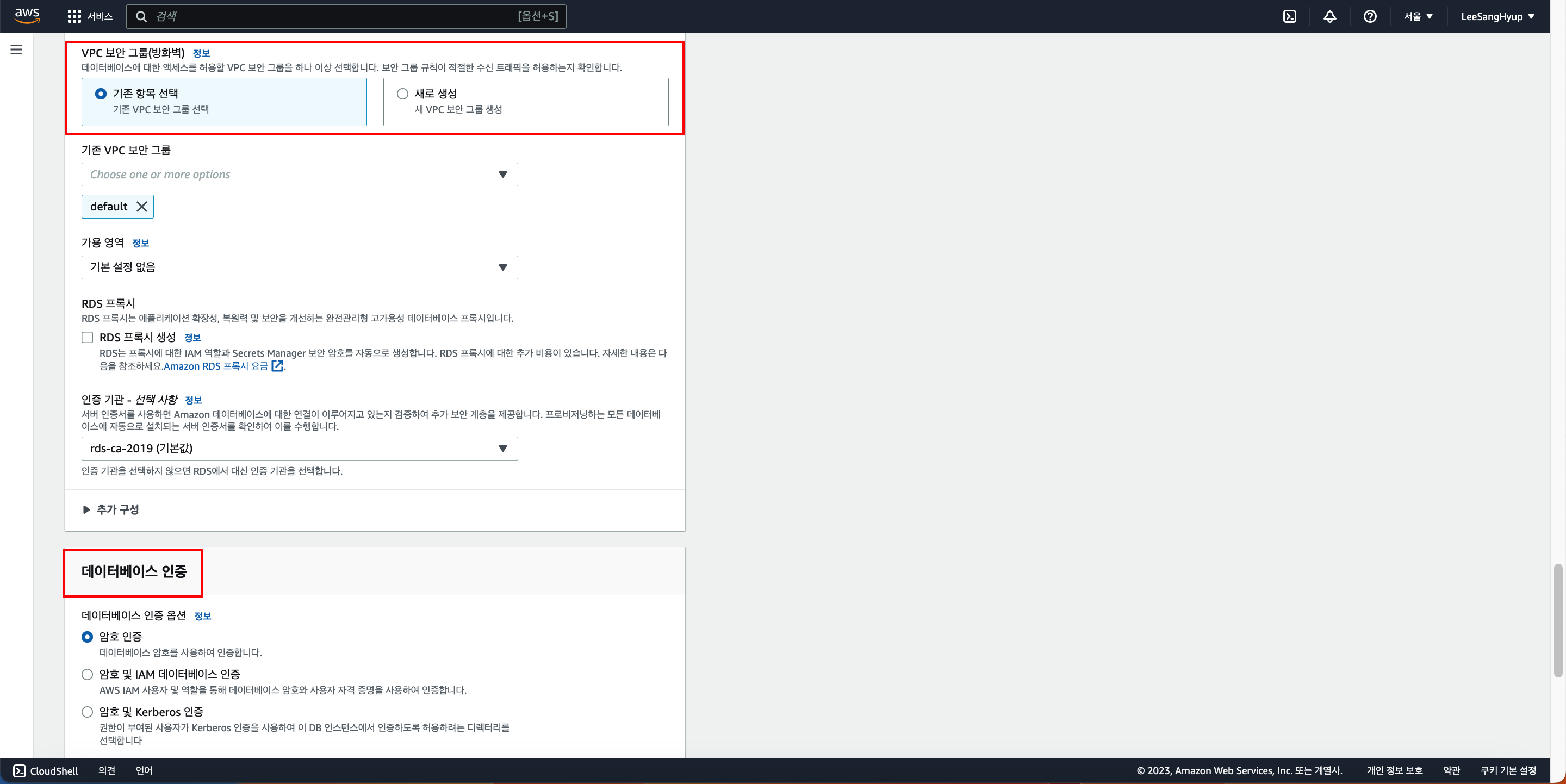
보안 그룹도 기존에 존재하던 거와 연결할 수 있으며, 데이터베이스 인증 방식은 암호 인증 선택
데이터베이스 생성 클릭
Parameter Store에 환경 설정
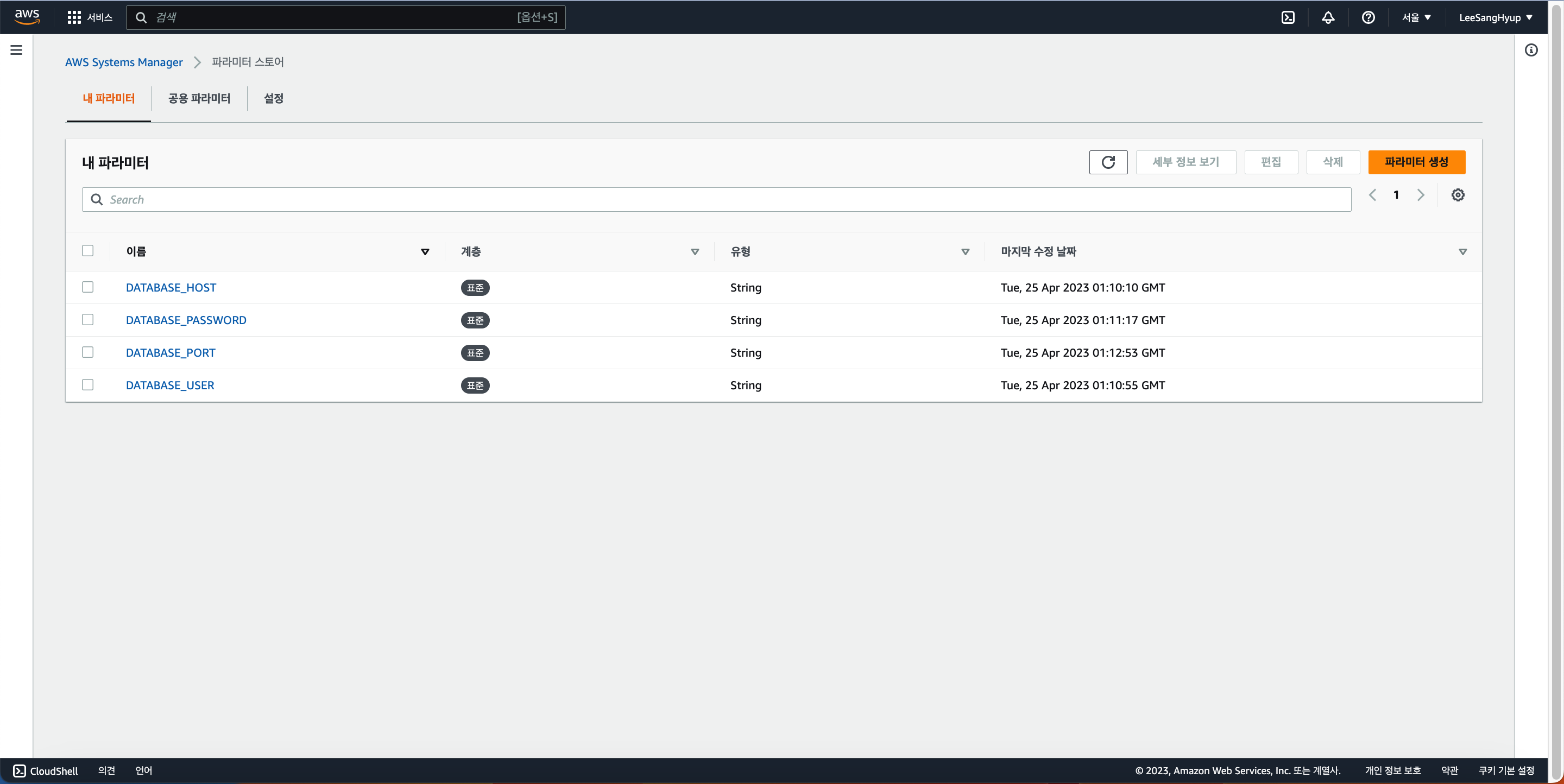
검색 창에 Parameter Store 입력 후 오른쪽 상단에 파라미터 생성 클릭
이름 -> appspec.yml가 실행할 스크립트에 있는 환경 변수 이름 기입
값 -> 이전에 생성한 RDS 값 입력
> 이후 파라미터 생성 클릭
예)
이름 : DETABASE_HOST
생성 완료 시 밑에 사진처럼 생성
깃허브에 appspec.yml이 인식할 수정한 스크립트 파일 push
> 환경 변수 이름은 Parameter Store에 추가한 이름,
> 값은 AWS SSM 파라미터 스토어에서 값을 가져와 환경 변수를 내보내는 셸 명령어
결과
AWS Parameter Store 장점
1. 보안: Parameter Store는 데이터를 안전하게 저장하기 위한 다양한 기능을 제공합니다. 예를 들어, AWS KMS를 사용하여 데이터를 암호화하고, IAM을 사용하여 액세스 권한을 관리할 수 있습니다.
2. 중앙 집중화된 관리: Parameter Store를 사용하면 설정 데이터를 중앙 집중화하여 관리할 수 있습니다. 이를 통해 여러 시스템에서 사용되는 설정 데이터를 효율적으로 관리할 수 있습니다.
3. 확장성: Parameter Store는 대규모 인프라스트럭처에서도 높은 확장성을 제공합니다. 필요에 따라 설정 데이터를 추가하거나 업데이트할 수 있습니다.
4. 유연성: Parameter Store는 다양한 데이터 형식을 지원합니다. 예를 들어, 문자열, JSON, 암호화된 문자열 등을 저장할 수 있습니다.
5. AWS 서비스와의 통합: Parameter Store는 AWS에서 제공하는 다양한 서비스와 통합됩니다. 예를 들어, AWS Lambda 함수에서 Parameter Store의 데이터를 사용할 수 있습니다.
배포 자동화란 한 번의 클릭 혹은 명령어 입력을 통해 전체 배포 과정을 자동으로 진행하는 것을 말합니다.
배포자동화 장점
먼저 수동적이고 반복적인 배포 과정을 자동화함으로써 시간이 절약됩니다.
휴먼 에러(Human Error)를 방지할 수 있습니다. 여기서 휴먼 에러란 사람이 수동적으로 배포 과정을 진행하는 중에 생기는 실수를 뜻합니다. 배포 자동화를 통해 전체 배포 과정을 매번 일관되게 진행하는 구조를 설계하여 휴먼 에러 발생 가능성을 낮출 수 있습니다.
배포 자동화 파이프라인
파이프라인 구성 단계와 수행 작업
배포에서 파이프라인(Pipeline)이란 용어는 소스 코드의 관리부터 실제 서비스로의 배포 과정을 연결하는 구조를 뜻합니다.
파이프라인은 전체 배포 과정을 여러 단계(Stages)로 분리하는데, 각 단계는 파이프라인 안에서 순차적으로 실행되며, 단계마다 주어진 작업(Actions)을 수행합니다.
파이프라인을 여러 단계로 분리할 때, 대표적으로 쓰이는 세 가지 단계가 존재합니다.
Source 단계: Source 단계에서는 원격 저장소에 관리되고 있는 소스 코드에 변경 사항이 일어날 경우, 이를 감지하고 다음 단계로 전달하는 작업을 수행합니다.
Build 단계: Build 단계에서는 Source 단계에서 전달받은 코드를 컴파일, 빌드, 테스트하여 가공합니다. 또한 Build 단계를 거쳐 생성된 결과물을 다음 단계로 전달하는 작업을 수행합니다.
Deploy 단계: Deploy 단계에서는 Build 단계로부터 전달받은 결과물을 실제 서비스에 반영하는 작업을 수행합니다.
여기서 주의해야 할 점은 파이프라인의 단계는 상황과 필요에 따라 더 세분화되거나 간소화될 수 있다는 겁니다.
AWS 개발자 도구
AWS에는 개발자 도구 섹션이 존재합니다. 개발자 도구 섹션에서 제공하는 서비스를 활용하여 배포 자동화 파이프라인을 구축할 수 있습니다.
AWS 개발자 도구 서비스 목록
본격적인 배포 자동화 실습을 진행하기 전에, 배포 자동화 과에서 사용하는 AWS 서비스들에 대해서 간략하게 소개하는 시간을 가져보도록 하겠습니다.
CodeCommit
Source 단계를 구성할 때 CodeCommit 서비스를 이용합니다. CodeCommit은 GitHub과 유사한 서비스를 제공하는 버전 관리 도구입니다. CodeCommit과 GitHub의 차이점은 무엇일까요? 어떤 서비스가 우월하다기보다, 각 서비스가 가지는 장단점이 다릅니다.
GitHub과 비교했을 때 CodeCommit 서비스는 보안과 관련된 기능에 강점을 가집니다. 소스 코드의 유출이 크게 작용하는 기업에서는 매우 중요한 요소입니다. 다만 CodeCommit을 사용할 때는 과금 가능성을 고려해야 합니다. 프리티어 한계 이상으로 사용할 시 사용 요금이 부과될 수도 있습니다. 그런 이유로 사이드 프로젝트나 가볍게 작성한 소스 코드를 저장해야 할 경우에는 GitHub을 이용하는 것이 효과적이라고 볼 수 있습니다.
CodeBuild
Build 단계에서는 CodeBuild 서비스를 이용합니다. CodeBuild 서비스를 통해 유닛 테스트, 컴파일, 빌드와 같은 빌드 단계에서 필수적으로 실행되어야 할 작업을 명령어를 통해 실행할 수 있습니다.
CodeDeploy
Deploy 단계를 구성할 때는 기본적으로 다양한 서비스를 이용할 수 있습니다. 이번 실습에서는 CodeDeploy와 S3 서비스를 이용할 예정입니다. CodeDeploy 서비스를 이용하면 실행되고 있는 서버 애플리케이션에 실시간으로 변경 사항을 전달할 수 있습니다. 또한 S3 서비스를 통해 S3 버킷을 통해 업로드된 정적 웹 사이트에 변경 사항을 실시간으로 전달하고 반영할 수 있습니다.
먼저 테스트 주도 개발을 연습합니다. 직접 test/app.test.js를 수정하여 통과하지 않는 테스트를 모두 통과시키세요.
애플리케이션은 node.js로 작성되어 있습니다. node.js LTS 버전을 준비합니다.
먼저 애플리케이션의 의존성(dependency)을 설치해야 합니다. npm install 명령을 이용해 의존성을 설치합니다.
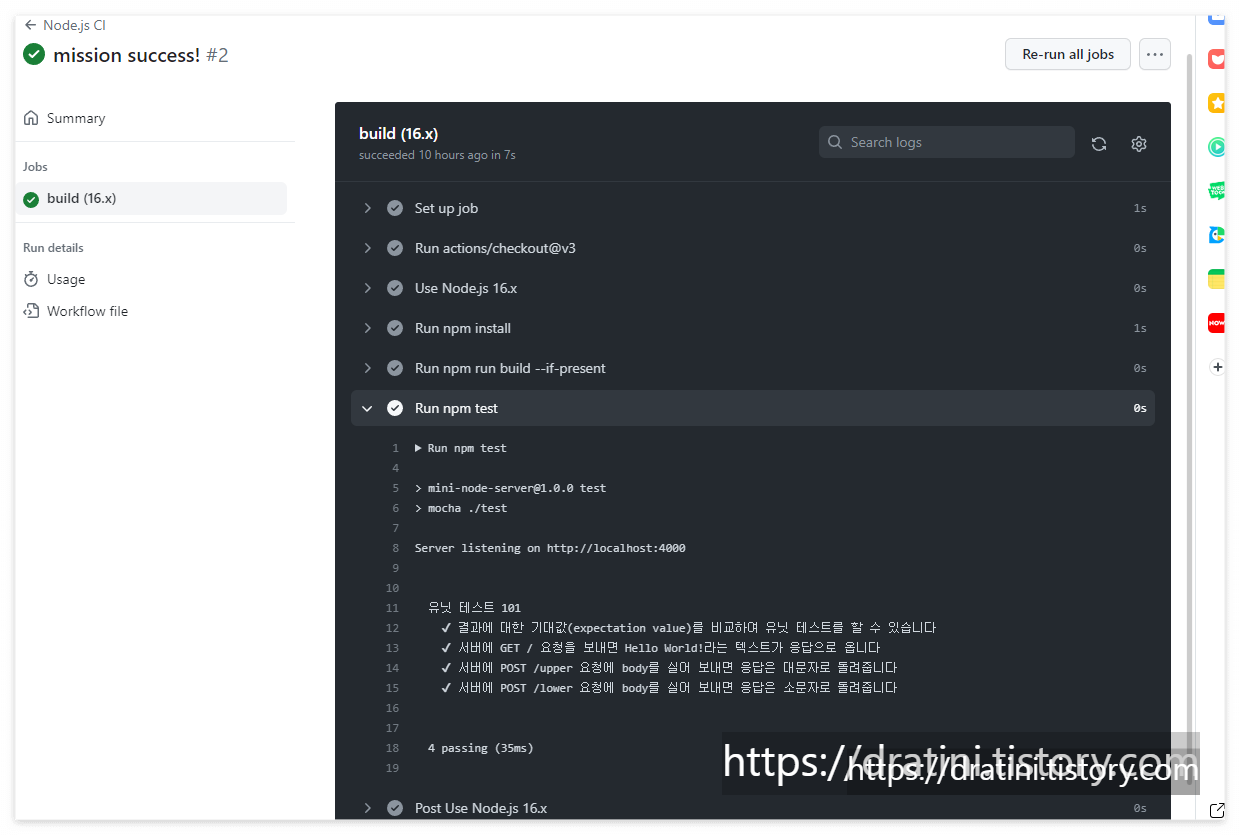
테스트가 통과하는지 확인하려면 npm test 명령을 이용합니다. 다음과 같이 테스트가 통과하지 않는 것을 먼저 확인하세요.
➜ npm test
> mini-node-server@1.0.0 test
> mocha ./test
Server listening on http://localhost:4000
유닛 테스트 101
1) 결과에 대한 기대값(expectation value)를 비교하여 유닛 테스트를 할 수 있습니다
2) 서버에 GET / 요청을 보내면 Hello World!라는 텍스트가 응답으로 옵니다
3) 서버에 POST /upper 요청에 body를 실어 보내면 응답은 대문자로 돌려줍니다
4) 서버에 POST /lower 요청에 body를 실어 보내면 응답은 소문자로 돌려줍니다
0 passing (35ms)
4 failing
1) 유닛 테스트 101
결과에 대한 기대값(expectation value)를 비교하여 유닛 테스트를 할 수 있습니다:
AssertionError: expected 2 to equal '기댓값이 채워지지 않았습니다'
at Context.<anonymous> (test/app.test.js:13:25)
at processImmediate (node:internal/timers:463:21)
(생략)
test/app.test.js 파일을 열어 통과하지 않는 테스트를 수정하세요. FILL_ME_IN이라고 적힌 곳에 기댓값을 적어주면 됩니다.
2. GitHub Action을 이용해서 Node.js CI를 적용하세요.
node 버전은 16 버전으로 반드시 지정해야 합니다.
다음 상황에서 GitHub Action이 트리거되어야 합니다.
master로 push 했을 경우
pull request를 보낸 경우
Pull Request로 제출하세요.
Getting Started
node.js 프로그램의 테스트를 위해서는 npm test 명령어를 CI, 즉 GitHub Action 상에서 자동으로 실행해줘야 합니다.
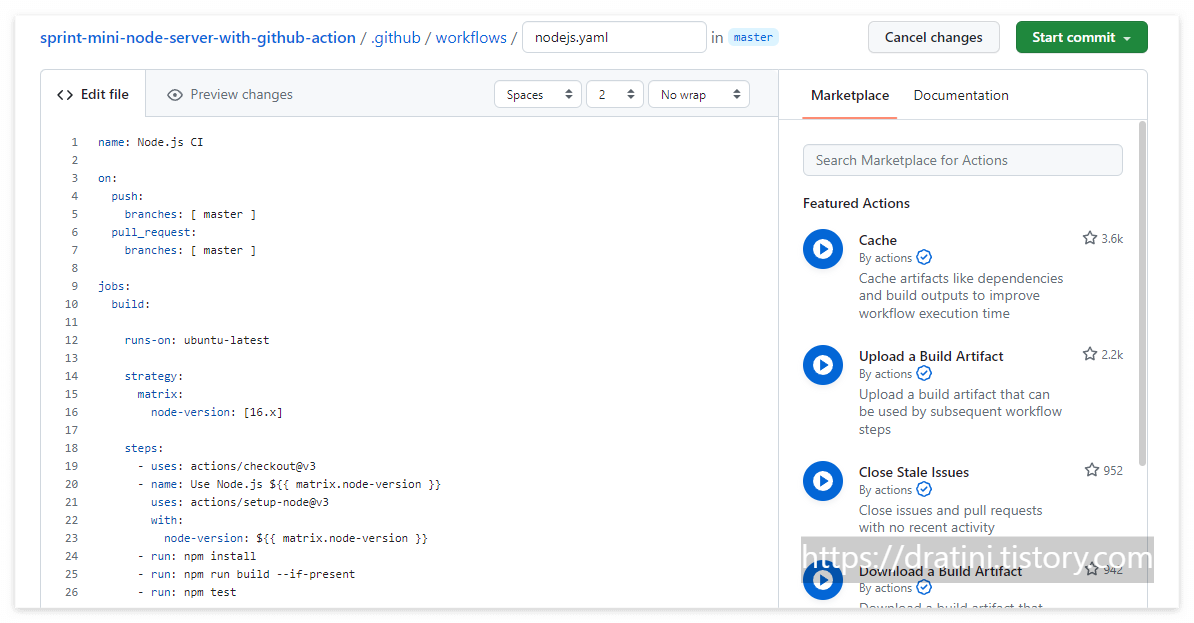
테스트를 진행할 레포지토리에 .github/workflows/nodejs.yaml 파일을 생성한다.
해당 파일의 구조는 다음과 같다.
name: Node.js CI #워크플로우의 이름을 적어준다.
on: # 워크플로우가 실행되는 EVENT에 대해 작성한다. master 브랜치에 push 또는 pull request가 올 경우 실행된다.
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs: # 실행되는 워크플로우의 작업을 지정한다. 여러 Job이 있을 경우, Default로 병렬 실행을 한다.
build: # build하는 job이 존재하고 그 아래에 실행되는 step이 존재하는 구조다.
runs-on: ubuntu-latest # 어떤 OS에서 실행될지 지정한다.
strategy: # 어떤 언어의 어떤 버전에서 테스트할지 지정할 수 있다.
matrix:
node-version: [16.x]
steps: # 어떤 액션들을 사용할지 지정한다. uses는 이미 만들어진 액션을 사용할 때 지정한다.
- uses: actions/checkout@v3
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
- run: npm install
- run: npm run build --if-present
- run: npm test
Jenkins는 오픈소스 자동화 서버입니다. 빌드, 테스트, 배포와 같은 소프트웨어 개발의 일부분을 자동화하는 데 도움을 주며, 지속적 통합과 지속적 배포를 돕습니다. 서버 기반의 시스템이며... (중략) ... Git과 같은 버전 관리 시스템을 지원합니다. 또한 쉘 스크립트를 실행할 수 있습니다.
테스트를 통해 결함과 버그를 조기에 발견할 수 있으며, 이는 개발자의 생산성을 향상할 수 있습니다.
제품의 결함과 버그를 발견하고 수정하는 것은 소프트웨어의 품질을 보증하고, 더 안정적이고 사용하기 쉽게 만듭니다.
테스트 주도 개발 (Test Driven Development, TDD)
테스트 주도 개발이란 테스트가 기능의 디자인을 주도하는 반복적인 개발 방법론을 뜻합니다.
테스트 주도 개발의 필요성을 알기 위해선 TDD 이전의 개발 방식에 대해 학습할 필요가 있습니다.
기존 개발과정
기존의 개발 프로세스는 아래와 같습니다.
요구사항 분석
요구 사항을 토대로 디자인(설계)을 진행
설계에 맞추어 기능을 개발.
구현 완료 후 수동으로 기능을 테스트
원하는 대로 동작하지 않거나 문제가 발생하면 디버깅을 통해 원인을 파악하고 수정
3 - 4의 과정을 개발이 완료될 때까지 반복
기존 개발과정의 문제점
수동 테스트와 디버깅: 기능 개발 완료 후 수동으로 테스트하고 디버깅을 통해 원인을 파악하고 수정하는 과정이 시간이 많이 소요되었습니다. 그래서 개발 및 배포 속도가 느려지고, 프로젝트 전반에 걸친 효율성이 저하되었습니다.
통합 문제: 개별적으로 개발된 코드들을 일정 시점에 통합하는 과정에서 발생하는 문제점들이 있었습니다. 이러한 통합 과정에서 호환성 문제나 버그가 발생하기 쉬워, 추가적인 디버깅과 수정 작업이 필요했습니다.
협업의 어려움: 팀 간의 협업이 제한적이어서, 코드 통합 과정에서 문제가 발생할 확률이 높았습니다.
높은 유지보수 비용: 코드의 변경이나 수정이 빈번하게 발생할 때마다 수동으로 테스트를 수행하고 디버깅을 해야 하므로 유지보수 비용이 높습니다. 이는 개발 비용과 시간을 증가시키는 요인이 됩니다.
테스트 주도 개발 과정
기존의 개발 프로세스를 보완하기 위해 태어난 테스트 주도 개발(TDD)의 프로세스는 아래와 같습니다.
요구사항 분석
요구 사항을 토대로 디자인(설계)을 진행
설계를 기반으로 기능 테스트 진행
실패 시 다시 설계
테스트가 성공했다면 개발 진행
3 - 4의 과정을 개발이 완료될 때까지 반복
기존 개발환경에서 개선된 점
설계 → 개발 → 테스트로 이어지던 기존의 개발 프로세스를 설계 → 테스트 → 개발의 프로세스로 변경하여 버그를 조기에 발견하고 해결할 수 있게 되었습니다.
TDD의 설계 → 테스트 → 개발의 프로세스는 변경 점에 따라 테스트를 진행해야 하는 상황에 대한 부담을 줄여 주었습니다.
테스트 주도 개발 사이클
TDD의 테스트는 큰 단위의 문제를 작은 단위로 나누어, 지속적인 피드백을 통해 목표를 개선해 나가는 방향으로 진행됩니다.
테스트 주도 개발의 장점
더욱 명확한 기능과 구조를 설계할 수 있습니다.
재사용성이 고려된, 모듈화된 코드를 작성할 수 있습니다.
설계 수정 시간과 디버깅 시간의 단축
단위 테스트 기반의 테스트 코드를 작성하기 때문에 추후 프로그램에 문제가 발생할 경우, 각각의 모듈별로 테스트를 진행하면서 문제 지점을 쉽게 찾아낼 수 있습니다.
완성도 높은 설계
코드의 기능, 정의 등 구조적인 문제에 대하여 명확하게 접근할 수 있으며 다양한 예외상황에 대해서도 고려하게 되므로 이는 완성도 높은 설계로 이어집니다.
유지 보수의 용이성
프로젝트에 어떤 기능을 추가하는 등의 유지 보수를 해야 하는 상황이라면 항상 기존 코드들에 끼칠 영향에 대해 생각해야 합니다.
TDD 이전의 개발 방식에선 단순한 기능이라도 수정되거나, 추가되는 경우에는 많은 코드에 대하여 테스트를 진행해야 했으나, TDD를 진행한다면 변경 점에 따른 테스트를 진행해야 하는 상황에 대한 부담이 줄어들 수 있습니다.
테스트의 종류
TDD에 활용할 수 있는 테스트의 종류에 대해 알아봅니다. 단위 테스트와, 통합 테스트 그리고 E2E 테스트에 대해 알아봅니다.
단위 테스트
말 그대로 작은 단위의 테스트입니다. 검증이 필요한 코드에 대해 테스트 케이스를 작성하는 과정을 말합니다. 유닛 테스트의 장점으로는 즉각적인 피드백이 나오는 것을 들 수 있습니다. 다만, 하나의 메서드가 잘 작동함은 보장할 수 있지만 그들이 결합하는 시점에서도 잘 작동하는지에 대해서는 보장할 수 없기 때문에 염두에 두어야 합니다.
통합 테스트
모듈을 통합하는 과정에서 모듈 간 호환성의 문제를 찾아내기 위해 수행되는 테스트입니다.
그래서 단위 테스트에서 찾지 못하는 통합 시 발생하는 버그 등을 찾을 수 있습니다.
단위 테스트 및 통합 테스트 시 사용하는 도구
mocha, chai (JavaScript)
JUnit (Java)
E2E 테스트 (End To End Test)
전체 시스템이 제대로 동작하는지 확인하기 위한 테스트입니다. 그래서 사용자의 입장에서 사용자가 사용하는 상황을 가정하고 시뮬레이션을 진행합니다.
장점
실제 상황에서 발생할 수 있는 에러를 미리 발견할 수 있다.
단점
테스트 작성 시 들어가는 비용이 너무 많습니다. 수행 속도가 느립니다. "실패했다"라는 결과만 있기 때문에 피드백의 질이 낮습니다.