데이터 파이프라인?
데이터 파이프라인은 여러 데이터 소스로부터 가공되지 않은 데이터를 수집해 전처리를 거쳐 데이터 웨어하우스와 같은 별도의 데이터 저장소로 이전하는 과정을 의미한다.
데이터 파이프라인을 사용하는 이유는 간단하다. 데이터를 수집하고, 가공하고, 적재하는 일련의 과정을 시스템화시켜서 데이터 분석을 효율적으로 하기 위해서 사용한다.
OLTP와 OLAP
데이터 파이프라인은 크게 온라인 트랜잭션 처리(OLTP)와 온라인 분석 처리(OLAP)로 나뉜다.
OLTP는 실시간으로 발생하는 트랜잭션 데이터를 처리하는데 초점을, OLAP는 대량의 데이터를 분석하고 요약 정보를 생성하는 데에 초점을 맞춘다.
| OLTP | OLAP | |
| 목적 | CRUD 작업과 같은 트랜잭션 처리 | 데이터 분석, 빅데이터 수집 |
| 데이터 종류 | 정형적이며, 정규화된 데이터 | 정형 및 비정형 데이터 |
| 특징 | 테이블 간 관계, 데이터의 무결성, 정규화 여부가 중요 | 빠른 분석과, 다차원 정보 제공이 중요 |
정형 데이터와 비정형 데이터
정형 데이터는 정해진 규칙에 따라 잘 정리된 데이터로, 날짜, 이름, 주소 등과 같이 해당 속성에 들어갈 값이 예측 가능하고 의미를 알기 쉬운 데이터를 말한다.
반면, 비정형 데이터는 문서(JSON, 텍스트)의 형태를 띠거나, 아예 음성이나 영상과 같은 바이너리 형식의 데이터일 수도 있다. 즉, 가공과 분석이 어렵다. 그러나 비즈니스에 필요한 정보를 얻어내기 위해선 비정형데이터를 분석해야하는 경우 또한 많기 때문에 요즘은 빅데이터 도구를 사용해 가공/분석 할 수 있도록 만든다.
데이터 파이프라인의 과정 : ETL과 ELT
ETL, ELT 각 알파벳의 뜻은 데이터 파이프라인의 각 과정인 데이터의 추출(Extraction), 변환(Transformation), 로드(Loading) 를 말한다.
ETL은 데이터를 원본에서 추출한 뒤 변환하고, 그 다음 목적지에 로드하는 과정입니다. ELT는 데이터를 먼저 추출하고 로드한 뒤, 목적지에서 변환하고, ETL은 데이터를 추출한 뒤에 변환하고, 로드한다.
데이터 파이프라인을 만들때 어떤 기술 및 도구를 선택하느냐에 따라 ETL과 ELT 중 적합한 방식을 선택하면 된다.
MLOps. 머신러닝과 데이터 파이프라인
DevOps는 개발과 운영을 따로 나누지 않고 개발의 생산성과 운영의 안정성을 최적화하기 위한 문화이자 방법론이다. 이 방법론에서 개발만 머신러닝 시스템으로 교체하면 그것이 바로 MLOps다.
그래서 MLOps 파이프라인의 과정들은 DevOps의 파이프라인 과정과 닮은 점이 많다.
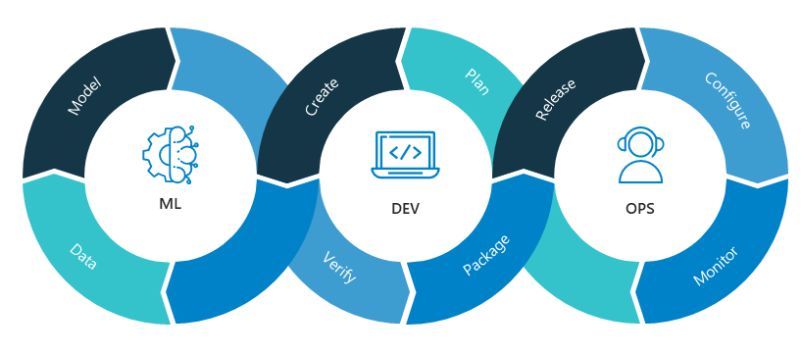
머신 러닝을 도입한 데이터 처리 파이프라인
- 데이터 분석
- 데이터의 이해를 위한 탐색적 데이터 분석(EDA, Exploratory Data Analysis)을 한다. 이때 모델에 필요한 데이터 스키마 및 특성을 이해한다.
- 데이터 준비 (추출 및 정제)
- 데이터 소스에서 관련 데이터를 추출(extract) 및 정제한다. 변환(transform), 집합(aggregate), 중복 제거 등의 과정을 거치게 된다.
- 모델 학습 및 튜닝
- 다양한 알고리즘을 구현하고, 하이퍼 파라미터를 조정(튜닝)하고 적용하여 학습된 모델을 만든다.
- 모델 평가 및 검증
- 모델 성능을 측정해, 배포에 적합한 수준인지를 검증한다.
- 모델 제공
- CI/CD 툴을 이용하여, 프로덕션 수준에서 이용할 수 있도록 파이프라인을 자동화시킨다.
- 모델 배포 및 모니터링
- 애플리케이션에서 사용 가능하도록 endpoint를 활성화해준다.
'DevOps' 카테고리의 다른 글
| [DevOps] 4/20 TIL : GitHub Action을 사용한 테스트 자동화 실습 (0) | 2023.04.21 |
|---|---|
| [DevOps] 4/20 TIL : CI/CD, 지속적 통합, 테스트 (0) | 2023.04.20 |
| [DevOps] 4/11 TIL : Docker 개념부터 기본 설치까지(Ubuntu) (0) | 2023.04.11 |
| [DevOps] 부트캠프 1차 팀프로젝트 회고 (0) | 2023.04.05 |
| [DevOps] CI/CD 파이프라인 (0) | 2023.03.18 |
